Runtime: Golang是如何处理系统调用阻塞的?
admin
- 7 minutes read - 1321 words我们知道在Golang中,当一个Goroutine由于执行 系统调用 而阻塞时,会将M从GPM中分离出去,然后P再找一个G和M重新执行,避免浪费CPU资源,那么在内部又是如何实现的呢?今天我们还是通过学习Runtime源码的形式来看下他的内部实现细节有哪些?
go version 1.15.6
我们知道一个P有四种运行状态,而当执行系统调用函数阻塞时,会从 _Prunning 状态切换到 _Psyscall,等系统调用函数执行完毕后再切换回来。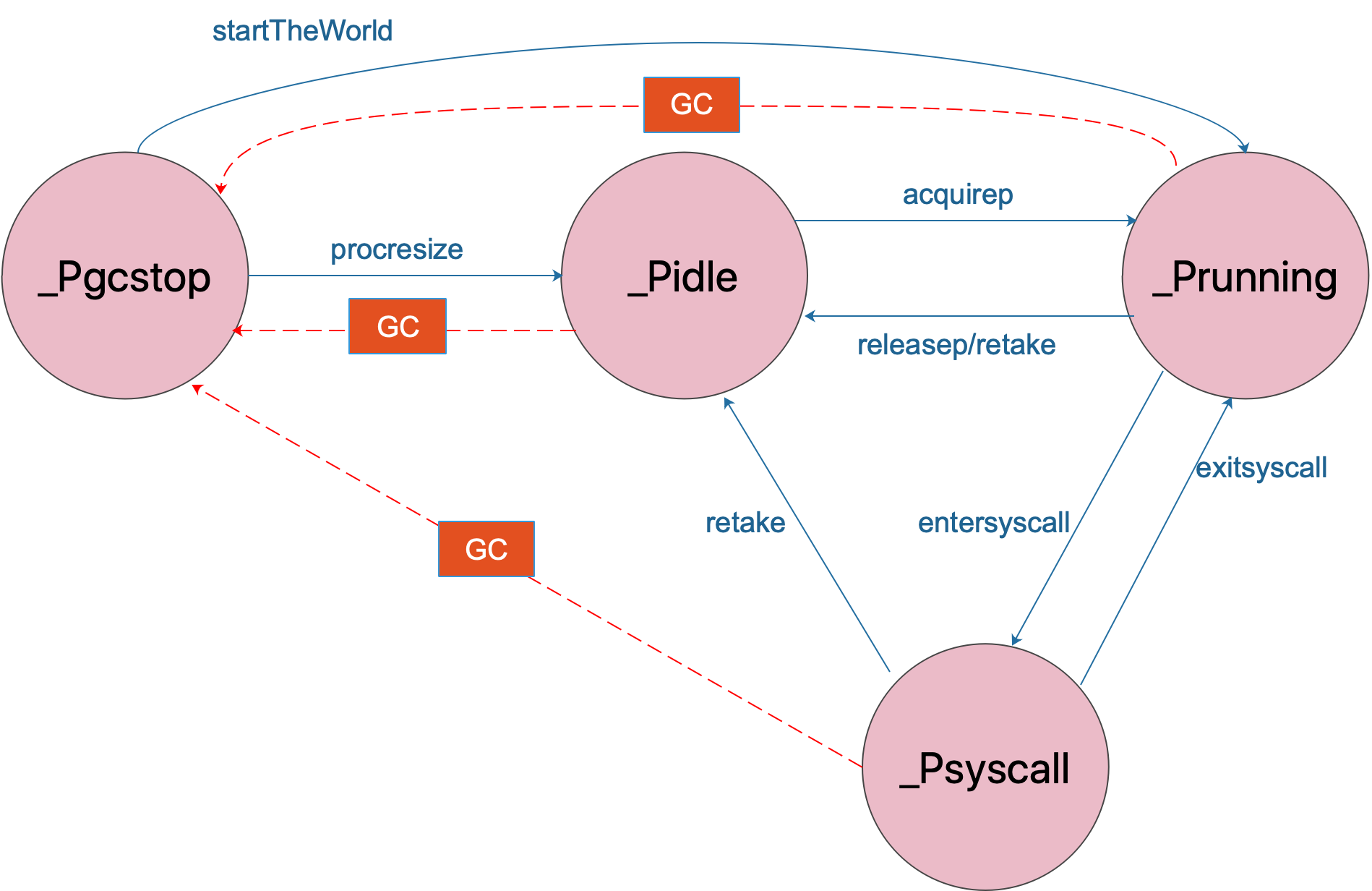 P的状态切换
P的状态切换
从上图我们可以看出 P 执行系统调用时会执行 [entersyscall()](https://github.com/golang/go/blob/go1.15.6/src/runtime/proc.go#L3134-L3142) 函数(另还有一个类似的阻塞函数 entersyscallblock() ,注意两者的区别)。当系统调用执行完毕切换回去会执行 exitsyscall() 函数,下面我们看一下这两个函数的实现。
进入系统调用
// Standard syscall entry used by the go syscall library and normal cgo calls.
//
// This is exported via linkname to assembly in the syscall package.
//
//go:nosplit
//go:linkname entersyscall
func entersyscall() {
reentersyscall(getcallerpc(), getcallersp())
}
当通过Golang标准库 syscall 或者 cgo 调用时会执行 entersyscall() 函数,并通过 go:linkname 方式导出为标准包。此函数只是对 [reentersyscall()](https://github.com/golang/go/blob/go1.15.6/src/runtime/proc.go#L3037-L3132) 函数的封装,我们看下这个函数实现了什么。
函数注释比较多,这里只帖子重点的一部分
// The goroutine g is about to enter a system call.
// Record that it's not using the cpu anymore.
// This is called only from the go syscall library and cgocall,
// not from the low-level system calls used by the runtime.
//
// Entersyscall cannot split the stack: the gosave must
// make g->sched refer to the caller's stack segment, because
// entersyscall is going to return immediately after.
//
// Nothing entersyscall calls can split the stack either.
// We cannot safely move the stack during an active call to syscall,
// because we do not know which of the uintptr arguments are
// really pointers (back into the stack).
// In practice, this means that we make the fast path run through
// entersyscall doing no-split things, and the slow path has to use systemstack
// to run bigger things on the system stack.
//
// reentersyscall is the entry point used by cgo callbacks, where explicitly
// saved SP and PC are restored. This is needed when exitsyscall will be called
// from a function further up in the call stack than the parent, as g->syscallsp
// must always point to a valid stack frame. entersyscall below is the normal
// entry point for syscalls, which obtains the SP and PC from the caller.
从注释我们得知以下信息:
- 调用此函数,
goroutine即将进入系统调用,将不会使用P。此函数只能通过标准的syscall库和cgocall调用 entersyscall()函数是禁止栈分裂的,gosave()函数必须将g->sched指向它的调用者的栈段,这是因为entersyscall()函数返回时要使用(不清楚的话,可以点击 这里)reentersyscall()函数是cgo的回调执行函数,它保存了已经恢复的SP/PC。reentersyscall()是不允许分裂的go:nosplit
//go:nosplit
func reentersyscall(pc, sp uintptr) {
_g_ := getg()
// Disable preemption because during this function g is in Gsyscall status,
// but can have inconsistent g->sched, do not let GC observe it.
_g_.m.locks++
// Entersyscall must not call any function that might split/grow the stack.
// (See details in comment above.)
// Catch calls that might, by replacing the stack guard with something that
// will trip any stack check and leaving a flag to tell newstack to die.
_g_.stackguard0 = stackPreempt
_g_.throwsplit = true
// Leave SP around for GC and traceback.
// 更新 g.sched 相关信息,后期需要读取这些信息
save(pc, sp)
// 记录g的系统调用SP/PC
_g_.syscallsp = sp
_g_.syscallpc = pc
// 设置g的状态为 _Gsyscall
casgstatus(_g_, _Grunning, _Gsyscall)
if _g_.syscallsp < _g_.stack.lo || _g_.stack.hi < _g_.syscallsp {
systemstack(func() {
print("entersyscall inconsistent ", hex(_g_.syscallsp), " [", hex(_g_.stack.lo), ",", hex(_g_.stack.hi), "]n")
throw("entersyscall")
})
}
if trace.enabled {
systemstack(traceGoSysCall)
// systemstack itself clobbers g.sched.{pc,sp} and we might
// need them later when the G is genuinely blocked in a
// syscall
save(pc, sp)
}
if atomic.Load(&sched.sysmonwait) != 0 {
systemstack(entersyscall_sysmon)
save(pc, sp)
}
if _g_.m.p.ptr().runSafePointFn != 0 {
// runSafePointFn may stack split if run on this stack
systemstack(runSafePointFn)
save(pc, sp)
}
// 更新与当前g关联P的执行调用系统调用次数
_g_.m.syscalltick = _g_.m.p.ptr().syscalltick
_g_.sysblocktraced = true
// 设置当前 m 所关联的 P 为下次优先使用的P(m.oldp = p), 实现亲和性
pp := _g_.m.p.ptr()
pp.m = 0
_g_.m.oldp.set(pp)
// 解除 m 与 p 的关联
_g_.m.p = 0
// 修改P的状态为 _Psyscall
atomic.Store(&pp.status, _Psyscall)
if sched.gcwaiting != 0 {
systemstack(entersyscall_gcwait)
save(pc, sp)
}
_g_.m.locks--
}
主要有以下工作:
- 在开始前需要进行
_g_.m.locks++, 以防止GC,函数执行结束时再减少一个锁 - 要进行禁止栈分裂
- 通过
save()函数将当前调度需要的信息暂存到_g_.sched - 修改
G和P的状态为系统调用状态 - 将本次
m绑定的 P 保存到_g_.oldp字段中,以备系统调用完毕后可以优先使用当前P继续执行
退出系统调用
当一个goroutine系统调用结束后,需要再次将GM重新与P关联继续执行,Golang 为了亲和性,会优先与上次执行的P绑定,如果上次关联的 P 正在被使用,这时再考虑重新找一个新的P 关联。
// The goroutine g exited its system call.
// Arrange for it to run on a cpu again.
// This is called only from the go syscall library, not
// from the low-level system calls used by the runtime.
//
// Write barriers are not allowed because our P may have been stolen.
//
// This is exported via linkname to assembly in the syscall package.
//
//go:nosplit
//go:nowritebarrierrec
//go:linkname exitsyscall
func exitsyscall() {}
同 reentersyscall() 函数一样,exitsyscall() 函数也是通过调用go的标准系统调用库实现的,而不是使用底层的runtime调用方法。
func exitsyscall() {
_g_ := getg()
_g_.m.locks++ // see comment in entersyscall
if getcallersp() > _g_.syscallsp {
throw("exitsyscall: syscall frame is no longer valid")
}
// 重置g阻塞时间为0
_g_.waitsince = 0
// 取出上次关联的P,优先使用
oldp := _g_.m.oldp.ptr()
_g_.m.oldp = 0
// 与原来的P进行关联
if exitsyscallfast(oldp) {
if trace.enabled {
if oldp != _g_.m.p.ptr() || _g_.m.syscalltick != _g_.m.p.ptr().syscalltick {
systemstack(traceGoStart)
}
}
// There's a cpu for us, so we can run.
_g_.m.p.ptr().syscalltick++
// We need to cas the status and scan before resuming...
// G 的状态恢复为 _Grunning
casgstatus(_g_, _Gsyscall, _Grunning)
// Garbage collector isn't running (since we are),
// so okay to clear syscallsp.
_g_.syscallsp = 0
_g_.m.locks--
if _g_.preempt {
// restore the preemption request in case we've cleared it in newstack
_g_.stackguard0 = stackPreempt
} else {
// otherwise restore the real _StackGuard, we've spoiled it in entersyscall/entersyscallblock
_g_.stackguard0 = _g_.stack.lo + _StackGuard
}
_g_.throwsplit = false
if sched.disable.user && !schedEnabled(_g_) {
// Scheduling of this goroutine is disabled.
Gosched()
}
return
}
_g_.sysexitticks = 0
if trace.enabled {
// Wait till traceGoSysBlock event is emitted.
// This ensures consistency of the trace (the goroutine is started after it is blocked).
for oldp != nil && oldp.syscalltick == _g_.m.syscalltick {
osyield()
}
// We can't trace syscall exit right now because we don't have a P.
// Tracing code can invoke write barriers that cannot run without a P.
// So instead we remember the syscall exit time and emit the event
// in execute when we have a P.
_g_.sysexitticks = cputicks()
}
_g_.m.locks--
// Call the scheduler.
// 在g0上调用 exitsyscall0() 函数, 执行流程到这里的话,说明并没有找到空闲的P,此时需要将G和M进行解绑,分别入相应的队列等待下次执行
mcall(exitsyscall0)
// Scheduler returned, so we're allowed to run now.
// Delete the syscallsp information that we left for
// the garbage collector during the system call.
// Must wait until now because until gosched returns
// we don't know for sure that the garbage collector
// is not running.
// 以下信息必须等待调度器返回才可以重置,gc考虑
_g_.syscallsp = 0
_g_.m.p.ptr().syscalltick++
_g_.throwsplit = false
}
当系统调用返回时,通过函数 [exitsyscallfast()](https://github.com/golang/go/blob/go1.15.6/src/runtime/proc.go#L3307-L3345) 优先与上次关联的 oldp 进行关联,否则重新获取一个新的P。如果重新获取新P也失败的话,这时候就需要将GM进行解绑,分别入等待执行队列等待下次的调度执行。 exitsyscall 流程
exitsyscall 流程
有P
上面我们说过与P关联时会优先使用上次使用的P,这里我们先看下与oldp 绑定的逻辑:
//go:nosplit
func exitsyscallfast(oldp *p) bool {
_g_ := getg()
// Freezetheworld sets stopwait but does not retake P's.
if sched.stopwait == freezeStopWait {
return false
}
// Try to re-acquire the last P.
// 尝试与上次的P关联
if oldp != nil && oldp.status == _Psyscall && atomic.Cas(&oldp.status, _Psyscall, _Pidle) {
// There's a cpu for us, so we can run.
wirep(oldp)
exitsyscallfast_reacquired()
return true
}
// Try to get any other idle P.
if sched.pidle != 0 {
var ok bool
systemstack(func() {
// 获取另一个P
ok = exitsyscallfast_pidle()
if ok && trace.enabled {
if oldp != nil {
// Wait till traceGoSysBlock event is emitted.
// This ensures consistency of the trace (the goroutine is started after it is blocked).
for oldp.syscalltick == _g_.m.syscalltick {
osyield()
}
}
traceGoSysExit(0)
}
})
if ok {
return true
}
}
return false
}
可以看到这里优先通过调用 [wirep()](https://github.com/golang/go/blob/go1.15.6/src/runtime/proc.go#L4474-L4497) 函数实现与上次使用的P关联。如果关联失败,再去看调度器里是否有空闲的P可以用(sched.pidle != 0)。如果有的话,则通过 [exitsyscallfast_pidle()](https://github.com/golang/go/blob/go1.15.6/src/runtime/proc.go#L3370-L3383) 函数里的 [pidleget()](https://github.com/golang/go/blob/go1.15.6/src/runtime/proc.go#L5107-L5118) 重新获取一个新的P进行关联。
// Try get a p from _Pidle list.
// Sched must be locked.
// May run during STW, so write barriers are not allowed.
//go:nowritebarrierrec
func pidleget() *p {
_p_ := sched.pidle.ptr()
if _p_ != nil {
sched.pidle = _p_.link
atomic.Xadd(&sched.npidle, -1) // TODO: fast atomic
}
return _p_
}
以上是有P可以关联的情况。
无P
如果所有的 P 都处于繁忙状态,可能无法获取空闲的P,这时就不得不先将GM解除关联,然后放入各自的等待队列里,等待下次的调度。实现函数为 [exitsyscall0()](https://github.com/golang/go/blob/go1.15.6/src/runtime/proc.go#L3385-L3417), 此函数需要在系统栈上执行。
// exitsyscall slow path on g0.
// Failed to acquire P, enqueue gp as runnable.
//
//go:nowritebarrierrec
func exitsyscall0(gp *g) {
_g_ := getg()
// G 状态为等待执行状态
casgstatus(gp, _Gsyscall, _Grunnable)
// 解除m与G的关联
dropg()
lock(&sched.lock)
var _p_ *p
if schedEnabled(_g_) {
_p_ = pidleget()
}
if _p_ == nil {
// 将g 放放全局运行队列
globrunqput(gp)
} else if atomic.Load(&sched.sysmonwait) != 0 {
atomic.Store(&sched.sysmonwait, 0)
notewakeup(&sched.sysmonnote)
}
unlock(&sched.lock)
// 这里再检查一次是否有p可用,有的话,正好重新再获取一个G立即执行
if _p_ != nil {
acquirep(_p_)
execute(gp, false) // Never returns.
}
if _g_.m.lockedg != 0 {
// Wait until another thread schedules gp and so m again.
stoplockedm()
execute(gp, false) // Never returns.
}
// 停止M
stopm()
// 重新调度
schedule() // Never returns.
}
[stopm()](https://github.com/golang/go/blob/go1.15.6/src/runtime/proc.go#L1906-L1928) 函数会停止当前m执行,直到有新的G需要执行。m停止后被调用 [mput()](https://github.com/golang/go/blob/go1.15.6/src/runtime/proc.go#L5014-L5023) 函数将当前m放在一下 sched.midle 空闲列表里。
总结
- 当进入系统调用时,先记录下当前G 的调度信息,包括当前使用的P
- 退出系统调用时,优先使用上次使用的P;如果原来的P已被使用,则重新找一个新的P;如果无P可用,则先当前的GM关系先解除,放入各自的待执行队列,等待下次调度再执行。这里的执行队列为全局
sched。