Runtime: Golang 之 sync.Pool 源码分析
admin
- 8 minutes read - 1519 wordsPool 指一组可以单独保存和恢复的 临时对象。Pool 中的对象随时都有可能在没有收到任何通知的情况下被GC自动销毁移除。
多个goroutine同时操作Pool是并发安全的。
源文件为 [src/sync/pool.go](https://github.com/golang/go/blob/master/src/sync/pool.go) go version: 1.16.2
为什么使用Pool
在开发高性能应用时,经常会有一些完全相同的对象需要频繁的创建和销毁,每次创建都需要在堆中分配对象,等使用完毕后,这些对象需要等待GC回收。我们知道在Golang中使用三色标记法进行垃圾回收的,在回收期间会有一个短暂STW(stop the world)的时间段,这样就会导致程序性能下降。
那么能否实现类似数据库连接池这种效果,用来避免对象的频繁创建和销毁,达到尽可能的资源复用呢?为了实现这种需求,标准库中有了sync.Pool 这个数据结构。看名字很知道它是一个池。但是它和我们想象中的数据库连接池还是有些差别的。对于数据库连接池这种资源只要不手动释放就可以一直利用,但对于 sync.Pool 则不一样,主要是因为Pool里的对象是随时都有可能被销毁,即这些都 临时对象。只要进行了GC,就会出现对象销毁的情况。所以不用使用Pool当作数据库连接池。
总之记住一点:sync.Pool中的资源随时都有可能被销毁而消失,这是与我们日常所说的池最大的区别,切勿乱用。
sync.Pool 基本信息
与 Pool 相关的主要有三个常量,其中 allPoolsMu 是一个全局锁;对于 allPoos 和 oldPools 则是一个 *Pool 数组,主要用在当P数量发生变化(增加)时会导致一些P找不到自己对应的 localPool,会将当前 Pool 放入 allPools,这样便于当GC发生时对其进行清理。
var (
allPoolsMu Mutex
// allPools is the set of pools that have non-empty primary
// caches. Protected by either 1) allPoolsMu and pinning or 2)
// STW.
allPools []*Pool
// oldPools is the set of pools that may have non-empty victim
// caches. Protected by STW.
oldPools []*Pool
)
Pool 数据结构
// A Pool must not be copied after first use.
type Pool struct {
// 不允许复制
noCopy noCopy
// 池的固定大小, local 对应类似 poolLocal,是一个数组
local unsafe.Pointer // local fixed-size per-P pool, actual type is [P]poolLocal
localSize uintptr // size of the local array
victim unsafe.Pointer // local from previous cycle
victimSize uintptr // size of victims array
// New optionally specifies a function to generate
// a value when Get would otherwise return nil.
// It may not be changed concurrently with calls to Get.
// 可选项,当使用Get获取对象时调用此函数,返回值是一个接口,意味着可以返回任意内容。如果不指定此函数将返回nil。
// 不能在调用Get() 时修改此函数
New func() interface{}
}
一旦 Pool 被初始化后,后续将不可以被复制使用,这一点与 sync.Mutex 同步原语相同。注意这里有一个 noCopy 这字段,主要是用在一些go工具检测对象是否存在复制的问题。
Pool 最重要的两个字段为 local 和 victim,因为它们两个是用来存储空闲元素的, 两者均是 poolLocal 数组指针。
当GC时,Pool会先把 oldPools 中的 victim 中的对象移除,然后把全局变量 allPools 中的 local 的数据再给 victim,同时对 local 清空和 localSize 置0。如果 victim 的对象被Get取走的话,此对象将会被保留。localSize 表示数组的大小。
当前所有空闲可用的元素都在 local 中存储,获取时优先从这里获取。
local 字段存储的是一个 poolLocal 数组指针,数组长度即为P的个数即 runtime.GOMAXPROCS(0)。这样每个P都会有自己的数据,访问时,P 的编号 ID 对应数组下标索引,这样就可以实现无锁访问,这一点对我们理解下面的逻辑很重要。
type poolLocal struct {
// 内嵌结构体
poolLocalInternal
// Prevents false sharing on widespread platforms with
// 128 mod (cache line size) = 0 .
// 避免 false sharing
pad [128 - unsafe.Sizeof(poolLocalInternal{})%128]byte
}
poolLocal 包含一个 poolLocalInternal 字段,pad 字段提供 CPU 缓存对齐,从而避免 false sharing。
type poolLocalInternal struct {
// 私有对象,每个P都有,用于不同G执行get和put可以无锁操作
private interface{} // Can be used only by the respective P.
// 共享对象数组,每个P都有一个,允许其它P过来窃取
shared poolChain // Local P can pushHead/popHead; any P can popTail.
}
每个P都会有一个 poolLocalInternal 数据结构
poolLocalInternal 包含两个字段
private只能由当前P使用,类似P级别的缓存元素,可无锁访问share任何P都可以访问,但是只有本地P可以从链表队列头部[pushHead](https://github.com/golang/go/blob/master/src/sync/poolqueue.go#L228-L256)和[popHead](https://github.com/golang/go/blob/master/src/sync/poolqueue.go#L258-L269)访问,其它P只能从尾部[popTail](https://github.com/golang/go/blob/master/src/sync/poolqueue.go#L271-L309)访问。相当于本地P是生产者(1个),其它P是消费者(多个)。
type poolChain struct {
head *poolChainElt
tail *poolChainElt
}
type poolChainElt struct {
poolDequeue
next, prev *poolChainElt
}
type poolDequeue struct {
headTail uint64
vals []eface
}
可以看到 poolChain 是一个双端队列,head 指向头,tail 指向尾, 指向的元素为 poolChinElt 数据结构。结构中存放的对象是一个 poolDequeue,用来存放真正的数据。一个PoolDequeue 就是一个固定大小的环,其中 headTail 指向环的首位置,vals 表示环中的元素,为切片类型。环的大小为8倍数,最小为8,当环状队列写入满的时候,会创建一个原来大小两倍的环,见 [poolChain.pushHead()](https://github.com/golang/go/blob/master/src/sync/poolqueue.go#L228-L256)方法。
对于双端队列大概样子如下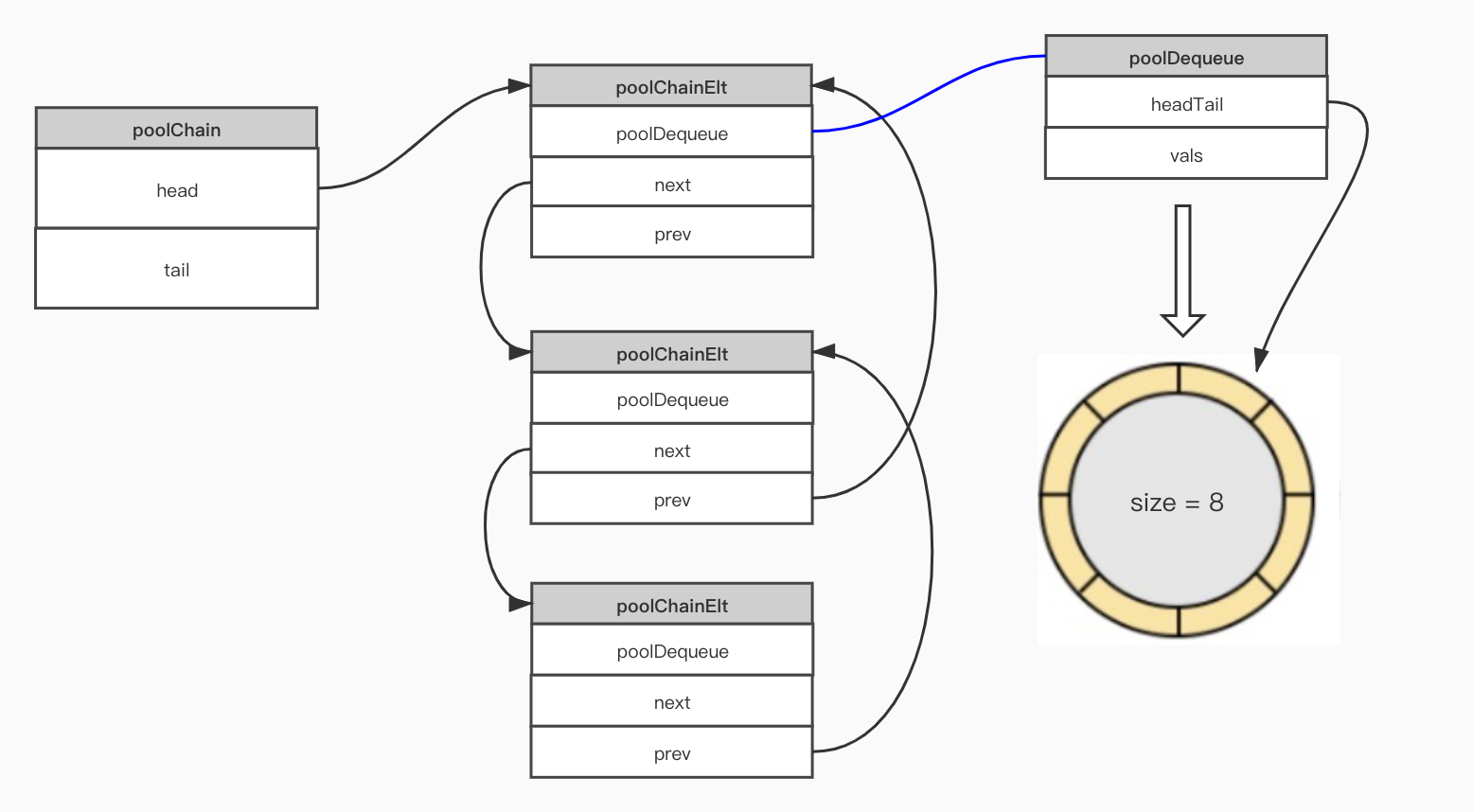 poolChain
poolChain
整个数据结构关联图如下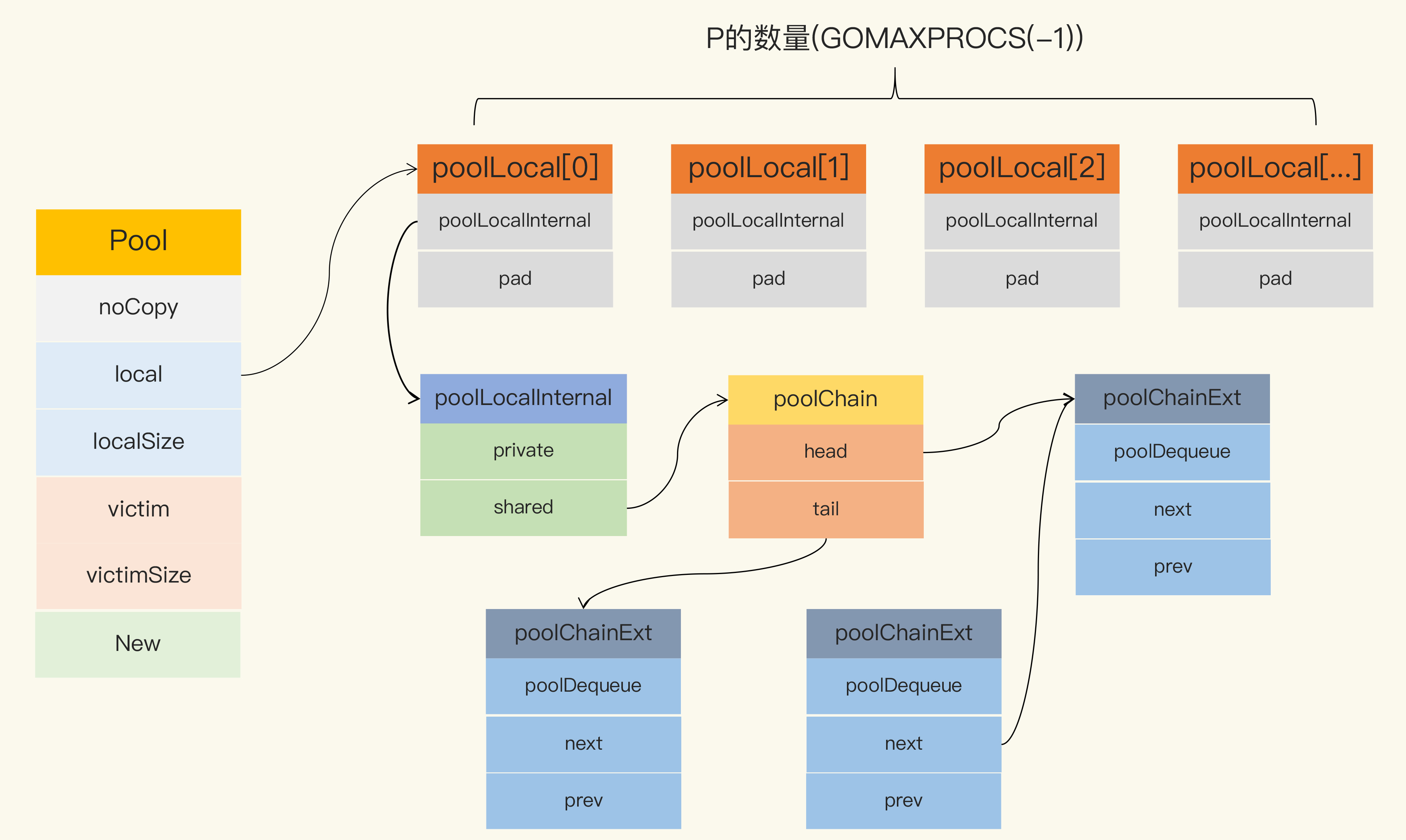 Pool struct
Pool struct
Pool 实现原理
对于 sync.Pool 的大概实现原理如下:
- 声明一个池,并设置好当池里没有对象的时候,调用一个生成对象的方法
Get() - 从池中通过 Get() 方法获取一个对象,如果当前P对应的 Pool 池中有对象则直接返回,如果没有,则使用声明池时的创建对象方法,创建一个对象后再将其返回
- 使用完毕后,再将对象通过Put() 方法放入池中以便利用。在调用
[pushHead()](https://github.com/golang/go/blob/master/src/sync/poolqueue.go#L228-L256)时,如果放入前记得最好对对象进行重置,使其恢复为首次创建时的状态
创建元素 New
Pool 有一个New变量,它的类型为 func() interface{}。函数返回值是一个接口类型,意味着我们可以返回任意内容。
此函数只有当Pool中没有空闲元素时才会调用,即创建一个元素并将其返回。如果不指定此变量,则默认会返回nil。
取元素 Get
当要从Pool中获取一个元素时需调用Get() 方法,注意如果没有设置New变量的话,将返回l默认的nil。
理想情况下,返回元素的默认值等于新创建元素的值,所以通常在使用完元素后,要重置初始化状态再放入池中。
// If Get would otherwise return nil and p.New is non-nil, Get returns
// the result of calling p.New.
func (p *Pool) Get() interface{} {
if race.Enabled {
race.Disable()
}
// 把当前goroutine固定在当前的P上
l, pid := p.pin()
// 1. 优先从当前P的 l.private 字段直接获取, 速度最快效率高
x := l.private
l.private = nil
if x == nil {
// 2. 获取不到,再从当前P的 share 头部获取一个(主要出于时间局部性考虑)
// Try to pop the head of the local shard. We prefer
// the head over the tail for temporal locality of
// reuse.
x, _ = l.shared.popHead()
if x == nil {
// 3. 仍获取不到,就从其它的P窃取一个,效率低
x = p.getSlow(pid)
}
}
// 解除goroutine与p绑定
runtime_procUnpin()
if race.Enabled {
race.Enable()
if x != nil {
race.Acquire(poolRaceAddr(x))
}
}
// 4. 最后仍没有获取到,直接创建一个
if x == nil && p.New != nil {
x = p.New()
}
return x
}
在获取元素前调用 [pin()](https://github.com/golang/go/blob/go1.16.2/src/sync/pool.go#L192-L207)方法将此goroutine固定在当前P上,避免查找元素期间当前G被其它的 P 执行。固定的好处就是查找元素期间直接得到跟这个 P 相关的 local。
func (p *Pool) pin() (*poolLocal, int) {
pid := runtime_procPin()
// In pinSlow we store to local and then to localSize, here we load in opposite order.
// Since we've disabled preemption, GC cannot happen in between.
// Thus here we must observe local at least as large localSize.
// We can observe a newer/larger local, it is fine (we must observe its zero-initialized-ness).
s := runtime_LoadAcquintptr(&p.localSize) // load-acquire
l := p.local // load-consume
if uintptr(pid) < s {
return indexLocal(l, pid), pid
}
return p.pinSlow()
}
先是调用 runtime_procPin() 函数将当前goroutine绑定到P上,并获得 pid。
pin() 方法在执行的时候,会检查如果当前 pid 小于 localSize,说明已存在对应的local直接返回。否则说明当前 P 是新创建的(runtime.GOMAXPROCS),所以缺少自己的poolLocal(),这时就需要调用 pinSlow() 来创建一个。上面我们讲过 local 字段是一个数组poolLocal, 表示每个P都有一个自己的 poolLocal。
func (p *Pool) pinSlow() (*poolLocal, int) {
// 解除pin
runtime_procUnpin()
// 加全局锁
allPoolsMu.Lock()
defer allPoolsMu.Unlock()
// 重新绑定pin
pid := runtime_procPin()
// poolCleanup won't be called while we are pinned.
s := p.localSize
l := p.local
// 重新检查 如果当前pid值<localSize, 说明对应的 poolLocal 已存在,直接返回
if uintptr(pid) < s {
return indexLocal(l, pid), pid
}
// 当前Pool.local不存在,先将当前Pool对象放入 allPools 中,后期进行清理
if p.local == nil {
allPools = append(allPools, p)
}
// If GOMAXPROCS changes between GCs, we re-allocate the array and lose the old one.
// 如果在GC期间,P 的数量发生变化,那么将会重新分配数据,从而丢失旧数组
// 当前P的数量
size := runtime.GOMAXPROCS(0)
// 创建当前P数量个poolLocal
local := make([]poolLocal, size)
// 将新创建的 localPool 数组首个元素地址赋值给 &Pool.local 字段,同时也更新 Pool.localSize 字段值
// 这里表示使用新的Pool.local 和Pool.localSize
atomic.StorePointer(&p.local, unsafe.Pointer(&local[0])) // store-release
runtime_StoreReluintptr(&p.localSize, uintptr(size)) // store-release
return &local[pid], pid
}
可以看到只有当P的数量发生变化,即增加个数时才会出现P找不到 localPool 的情况,这时将会重新分配一个当前P大小的 poolLocal 数组(实际上是切片类型)并赋值给 Pool.local,同时还有其大小 Pool.localSize ,而原来的 localPool 数组将丢弃。
Get 获取元素的顺序
- 先从
l.private取元素 - 若取不到,再从列表
l.share头部获取 - 还是取不到,就调用
p.getSlow()从其它P的share尾部执行popTail窃取一个 - 最后仍没有取到,直接能用指定的 p.New 函数创建一个并返回,如果未指定此变量,则返回
nil
从其它 P 窃取流程
// 从其它P窃取一个元素
func (p *Pool) getSlow(pid int) interface{} {
// See the comment in pin regarding ordering of the loads.
size := runtime_LoadAcquintptr(&p.localSize) // load-acquire
locals := p.local // load-consume
// Try to steal one element from other procs.
// 1. 从其它procs尝试窃取一个
for i := 0; i < int(size); i++ {
//
l := indexLocal(locals, (pid+i+1)%int(size))
if x, _ := l.shared.popTail(); x != nil {
return x
}
}
// Try the victim cache. We do this after attempting to steal
// from all primary caches because we want objects in the
// victim cache to age out if at all possible.
// 2. 如果没有偷到,则尝试从当前P的 vintim 中获取一个
size = atomic.LoadUintptr(&p.victimSize)
if uintptr(pid) >= size {
return nil
}
// 2.1 先从 victim 中的private获取,取不到再考虑从其它 victim 中的share中获取
locals = p.victim
l := indexLocal(locals, pid)
if x := l.private; x != nil {
l.private = nil
return x
}
// 2.2 再从 victim 中的share获取
for i := 0; i < int(size); i++ {
l := indexLocal(locals, (pid+i)%int(size))
if x, _ := l.shared.popTail(); x != nil {
return x
}
}
// Mark the victim cache as empty for future gets don't bother
// with it.
// 如果victim中都没有,则把这个victim标记为空,以后的查找可以快速跳过了
atomic.StoreUintptr(&p.victimSize, 0)
return nil
}
首先要遍历所有的 local,尝试从它们的 shared 弹出一个元素。如果还没找到一个,那么,就开始对 victim 下手了。
在 vintim 中查询可用元素的逻辑还是一样的,先从对应的 victim 的 private 查找,如果查不到,就再从其它 victim 的 shared 中查找。
存放元素 Put
调用 [Put()](https://github.com/golang/go/blob/go1.16.2/src/sync/pool.go#L89-L114) 方法将一个元素放入池中。
// Put adds x to the pool.
func (p *Pool) Put(x interface{}) {
if x == nil {
return
}
// 将goroutine固定在P上
l, _ := p.pin()
// 优先将元素放在 private,如果当前private为空的话
if l.private == nil {
l.private = x
x = nil
}
// 如果private已经有元素了,就将当前元素放在 share 列表的头部
if x != nil {
l.shared.pushHead(x)
}
runtime_procUnpin()
}
Put 的逻辑比较简单,如果private为nil 的话,就将元素放在private,否则放在share 列表的头部。
func (c *poolChain) pushHead(val interface{}) {
// 头指针对象
d := c.head
// 创建一个 Chain,并初始化环状元素
if d == nil {
// Initialize the chain.
// 初始化poolDequeue.vals 的长度为8
const initSize = 8 // Must be a power of 2
d = new(poolChainElt)
d.vals = make([]eface, initSize)
// c.head指针指向这个环形 poolChainElt
c.head = d
// c.tail 指针也指向这个环形 poolChainElt
storePoolChainElt(&c.tail, d)
}
// 存储到环中 poolDequeue.pushHead() 存储元素,如果返回false,则表示队列已满,需要扩容
if d.pushHead(val) {
return
}
// The current dequeue is full. Allocate a new one of twice
// the size.
// 队列已满,则创建两倍大小的新队列,并再次 poolDequeue.pushHead() 存储元素
newSize := len(d.vals) * 2
if newSize >= dequeueLimit {
// Can't make it any bigger.
// dequeueLimit = (1 << 32) / 4
newSize = dequeueLimit
}
// 将新创建的队列添加的头部,新对象prev指针指向原来的对象,原来对象(head)的d.next 指针指向新poolChainElt
d2 := &poolChainElt{prev: d}
d2.vals = make([]eface, newSize)
c.head = d2
storePoolChainElt(&d.next, d2)
d2.pushHead(val)
}
存储时需要先检查是否存在环状队列的情况,如果 c.head 是为 nil,则说明当前还没有环状队列,则需要初始化一个新的队列。
如果队列已存在,则直接调用 [poolDequeue.pushHead()](https://github.com/golang/go/blob/master/src/sync/poolqueue.go#L78-L107) 进行存储,如果返回值为false,说明队列已满放不下,这时则需要再创建两倍大小的环状对象,并将其作 poolChain.head 对象。
// pushHead adds val at the head of the queue. It returns false if the
// queue is full. It must only be called by a single producer.
func (d *poolDequeue) pushHead(val interface{}) bool {
ptrs := atomic.LoadUint64(&d.headTail)
head, tail := d.unpack(ptrs)
if (tail+uint32(len(d.vals)))&(1<<dequeueBits-1) == head {
// Queue is full.
return false
}
slot := &d.vals[head&uint32(len(d.vals)-1)]
// Check if the head slot has been released by popTail.
typ := atomic.LoadPointer(&slot.typ)
if typ != nil {
// Another goroutine is still cleaning up the tail, so
// the queue is actually still full.
return false
}
// The head slot is free, so we own it.
if val == nil {
val = dequeueNil(nil)
}
*(*interface{})(unsafe.Pointer(slot)) = val
// Increment head. This passes ownership of slot to popTail
// and acts as a store barrier for writing the slot.
atomic.AddUint64(&d.headTail, 1<<dequeueBits)
retu
这里也用到了大量的位运算操作,有兴趣的可以分析一下,这里不再详细介绍。
GC 影响
当前包文件 src/sync/pool.go 有一个[init()](https://github.com/golang/go/blob/go1.16.2/src/sync/pool.go#L272-L274) 函数,我们知道它在包引入时将自动优先执行,主要用来注册一个当GC发生对Pool元素清理的函数 [poolCleanup()](https://github.com/golang/go/blob/go1.16.2/src/sync/pool.go#L233-L257) 。
func init() {
runtime_registerPoolCleanup(poolCleanup)
}
func poolCleanup() {
// This function is called with the world stopped, at the beginning of a garbage collection.
// It must not allocate and probably should not call any runtime functions.
// Because the world is stopped, no pool user can be in a
// pinned section (in effect, this has all Ps pinned).
// Drop victim caches from all pools.
// STW期间,清除所有Pool的victim
for _, p := range oldPools {
p.victim = nil
p.victimSize = 0
}
// Move primary cache to victim cache.
// 将每个Pool的local复制给victim, 并将原local置为nil
for _, p := range allPools {
p.victim = p.local
p.victimSize = p.localSize
p.local = nil
p.localSize = 0
}
// The pools with non-empty primary caches now have non-empty
// victim caches and no pools have primary caches.
// 将所有allPools复制给oldPools,并将allPools清除
oldPools, allPools = allPools, nil
}
先是遍历清除每个Pool 的 victim 字段,然后通过遍历将 local 值给 victim,同时清除 local 字段,按同样的方法将allPolls的值给oldPools的值,并清除 allPools 的值。
使用 Pool 的坑
主要有两种坑,分别为 内存浪费 和 内存泄漏。
对于内存浪费如何理解呢?可能很奇怪,Pool不就是解决内存问题的么,怎么会浪费呢。回答这个问题需要从另一个角度看。假如是一个很大的 buffer 对象,但在使用时可能需要一个小的buffer对象就可以了。这种情况下我们可要根据使用对象的大小对其进行分级,如一类是8K大小的对象,另一类是16K大小的对象,需要哪种大小的对象时,直接获取相应大小的对应即可。这点在标准库 [net/http/server.go](https://github.com/golang/go/blob/617f2c3e35cdc8483b950aa3ef18d92965d63197/src/net/http/server.go#L814-L835) 中有此用法,它分别提供了2K和4K两种大小对象的Pool。 Pool
Pool
当然这种需要开发者提前对其大小有一定的评估才可以。
另一种坑是内存泄漏,例如我们将一个 bytes.Buffer 放在了Pool中,使用时添加了太多的内容,导致底层的byte slice很大,即使 Reset后放回Pool中,在下次进行GC之前,它会一直占用内存,就算GC发生后(GC时对象正处于使用中状态),也有可能长时间的存在,这种情况下就属于内存泄漏问题了。
所以在使用Pool时,尽量评估下对象的大小,如果对象太大,就没有必要再放入Pool 中了,直接把它交给GC彻底回收即可,否则就有点太浪费内存了。
参考资料
- https://mp.weixin.qq.com/s?__biz=MzA4ODg0NDkzOA==&mid=2247487149&idx=1&sn=f38f2d72fd7112e19e97d5a2cd304430&source=41
- https://time.geekbang.org/column/article/301716
- https://www.luozhiyun.com/archives/416
- https://zhuanlan.zhihu.com/p/99710992