k8s调度器 kube-scheduler 源码解析
admin
- 21 minutes read - 4429 words版本号:v1.27.2
Kubernetes 调度程序作为一个进程与其他主组件(例如 API 服务器)一起运行。它与 API 服务器的接口是监视具有空 PodSpec.NodeName 的 Pod,并且对于每个 Pod,它都会发布一个 Binding,指示应将 Pod 调度到哪里。
调度过程
+-------+
+---------------+ node 1|
| +-------+
|
+----> | Apply pred. filters
| |
| | +-------+
| +----+---------->+node 2 |
| | +--+----+
| watch | |
| | | +------+
| +---------------------->+node 3|
+--+---------------+ | +--+---+
| Pods in apiserver| | |
+------------------+ | |
| |
| |
+------------V------v--------+
| Priority function |
+-------------+--------------+
|
| node 1: p=2
| node 2: p=5
v
select max{node priority} = node 2
调度器入口
kubernetes 调度器入口文件位于 /cmd/kube-scheduler/scheduler.go,其中用到的核心库位于 /pkg/scheduler。
调用流程:
`app.NewSchedulerCommand()`
↓
`runCommand(cmd, opts, registryOptions...)`
↓
`cc, sched, err := Setup(ctx, opts, registryOptions...)`
↓
`sched, err := scheduler.New(cc.Client,...) `
↓
` Run(ctx, cc, sched)`
|
|
----> `sched.Run(ctx)` (/pkg/scheduler) -> `sched.SchedulingQueue.Run()`
↓
go wait.UntilWithContext(ctx, sched.scheduleOne, 0)
最后到达文件 /pkg/scheduler/scheduler.go#L241, 这里创建了一个 Scheduler 是我们重点关注的地方。
Scheduler 结构体
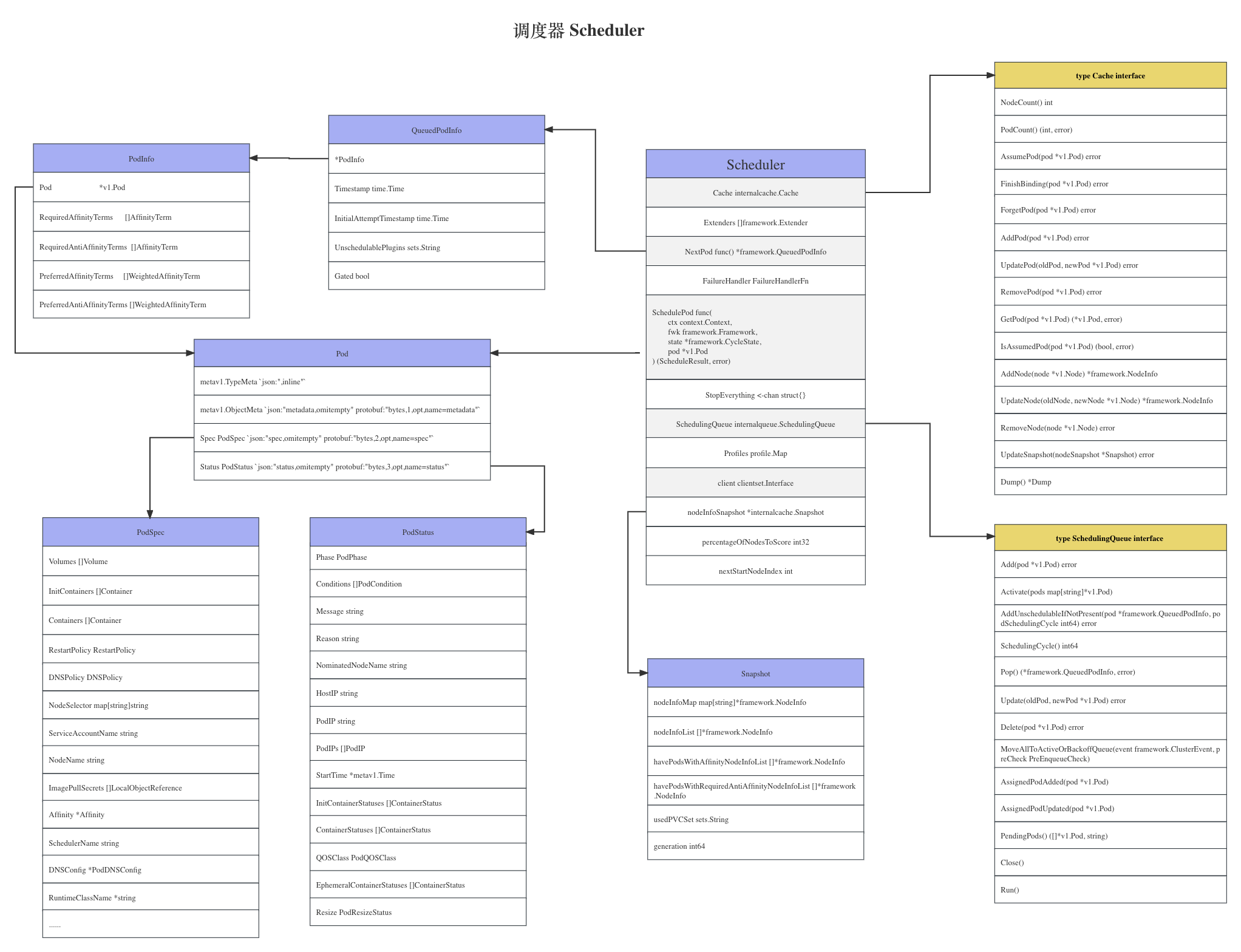
不过为了后面方便理解,我们先看一下 Scheduler结构体的结构。
从注释信息我们可以看到其主要功能是 watch未调度的pod,它将试图找一个合适的 Node ,然后将其写回到 api server。
// Scheduler watches for new unscheduled pods. It attempts to find
// nodes that they fit on and writes bindings back to the api server.
type Scheduler struct {
// 通过 NodeLister 和 Algorithm 将观察到通过 Cache 所做的任何更改
// It is expected that changes made via Cache will be observed
// by NodeLister and Algorithm.
Cache internalcache.Cache
// 扩展器是外部进程影响Kubernetes做出的调度决策的接口,通常是不由Kubernetes直接管理的资源所需要的。这种方式用的不多
Extenders []framework.Extender
// 以阻塞的形式获取下一个有效的待调度的Pod。这里不使用channel,主要是因为对一个pod的调度可能需要一些时间
// NextPod should be a function that blocks until the next pod
// is available. We don't use a channel for this, because scheduling
// a pod may take some amount of time and we don't want pods to get
// stale while they sit in a channel.
NextPod func() *framework.QueuedPodInfo
// 调度失败处理 Handler
// FailureHandler is called upon a scheduling failure.
FailureHandler FailureHandlerFn
// 试图将一个Pod调度到其中一个节点上,成功则返回 ScheduleResult, 否则返回带有失败原来的 FitError
// SchedulePod tries to schedule the given pod to one of the nodes in the node list.
// Return a struct of ScheduleResult with the name of suggested host on success,
// otherwise will return a FitError with reasons.
SchedulePod func(ctx context.Context, fwk framework.Framework, state *framework.CycleState, pod *v1.Pod) (ScheduleResult, error)
// Close this to shut down the scheduler.
StopEverything <-chan struct{}
// 等待被调度的Pod队列,也就是说只有从这个队列里获取的Pod才能被调度
// SchedulingQueue holds pods to be scheduled
SchedulingQueue internalqueue.SchedulingQueue
// 调度配置profiles
// Profiles are the scheduling profiles.
Profiles profile.Map
// api server 专用 client
client clientset.Interface
// 节点信息快照
nodeInfoSnapshot *internalcache.Snapshot
// 节点打分相关
percentageOfNodesToScore int32
nextStartNodeIndex int
}
通过结构体我们大概可以猜到一些信息:
- 调度中某些操作与
Cache有关,主要是性能优化考虑,设计文档参考/pkg/scheduler/internal/cache/interface.go - 通过
NextPod函数可以从调度队列SchedulingQueue里获取一个需要待调度的 Pod 信息,其结构体*framework.QueuedPodInfo内嵌了*PodInfo结构体,而*PodInfo又内嵌了*v1.Pod结构体,MakeNextPodFunc()函数 - 通过
SchedulePod函数对一个 Pod 进行调度,其中传递的Pod参数为*v1.Pod,调度成功返回ScheduleResult, 如果失败则返回*FitError* - 如果调度失败需要进行
FailureHandler处理 - 所有需要调度的Pod必须从
SchedulingQueue里获取 - 需要用 client 与
api server通讯,是不是需要保存节点与Pod绑定关系?因在结构体的注释提到过 api server - 调度器可能需要在一定的时机将其关闭
- Profiles 用在什么地方?
- 节点快照
nodeInfoSnapshot是干什么用的? - 节点打分
percentageOfNodesToScore,它是集群中可用节点的百分比阈值。一旦发现足够的节点可以满足调度一个 pod 的条件,调度器就会停止在集群中继续寻找更多的可用节点,以提高调度器的性能。无论这个阈值的值是多少,调度器始终至少尝试找到minFeasibleNodesToFind个可用节点。例如,如果集群大小为 500 个节点,PercentageOfNodesToScore的值为 30,则只需找到 150 个可行的节点,调度器就会停止继续寻找更多的可行节点。当值为0时,将使用默认百分比 (基于集群大小的5%–50%) 来评分节点,它将覆盖全局PercentageOfNodesToScore。如果没有设置,将使用全局PercentageOfNodesToScore。 - 其它
接着我们带着上面一些个人理解到的片面信息与疑问,看一下 Scheduler 的内部实现原理。
Scheduler 创建
了解了结构体后,我们再看下 Scheduler 的函数 New() 实现
我们先看一下函数原型
func New(client clientset.Interface,
informerFactory informers.SharedInformerFactory,
dynInformerFactory dynamicinformer.DynamicSharedInformerFactory,
recorderFactory profile.RecorderFactory,
stopCh <-chan struct{},
opts ...Option) (*Scheduler, error) {}
参数解释:
client 就是 api server 的客户端,一般是通过读取默认配置文件 $HOME/.kube/config 生成
informerFactory 一个 SharedInformerFactory,参考
dynInformerFactory Dynamic 客户端的 Shared 的 Informer
recorderFactory 一个 scheduler name 的事件记录器
stopCh 终止退出信号
opts 就是scheduler 的选项函数,对scheduler 进行初始化
对于返回结果就是一个 Scheduler 对象。
下面我们一块看一下其具体实现
配置选项初始化
函数选项式模式对调度器结构体初始化
// 函数选项式模块初始化调度器结构体
options := defaultSchedulerOptions
for _, opt := range opts {
opt(&options)
}
这里的 defaultSchedulerOptions 是一个单独的结构体,原型为
type schedulerOptions struct {
componentConfigVersion string
kubeConfig *restclient.Config
// Overridden by profile level percentageOfNodesToScore if set in v1.
percentageOfNodesToScore int32
podInitialBackoffSeconds int64
podMaxBackoffSeconds int64
podMaxInUnschedulablePodsDuration time.Duration
// Contains out-of-tree plugins to be merged with the in-tree registry.
frameworkOutOfTreeRegistry frameworkruntime.Registry
profiles []schedulerapi.KubeSchedulerProfile
extenders []schedulerapi.Extender
frameworkCapturer FrameworkCapturer
parallelism int32
applyDefaultProfile bool
}
这里有两个重要的字段,一个是 profiles 字段,它其实就是我们开发插件时指定的配置文件,参考 https://kubernetes.io/zh-cn/docs/reference/scheduling/config/,另一个是 extenders 字段。
profiles 字段
profiels 字段类型为 []schedulerapi.KubeSchedulerProfile,API文档为 https://kubernetes.io/zh-cn/docs/reference/config-api/kube-scheduler-config.v1/#kubescheduler-config-k8s-io-v1-KubeSchedulerProfile, 结构类型
// KubeSchedulerProfile is a scheduling profile.
type KubeSchedulerProfile struct {
SchedulerName string // 调度器名称
PercentageOfNodesToScore *int32 // 集群中可用节点的百分比阈值
Plugins *Plugins // 所有插件,包含启用和禁用
PluginConfig []PluginConfig // 每个插件的一组可选的自定义插件参数,如果省略则使用默认配置
}
从结构体大致就可以知道它其实是一个调度器切片,每个调度器都有一组 Plugins。
而这个 Plugins 结构为
type Plugins struct {
// PreEnqueue is a list of plugins that should be invoked before adding pods to the scheduling queue.
PreEnqueue PluginSet
// QueueSort is a list of plugins that should be invoked when sorting pods in the scheduling queue.
QueueSort PluginSet
// PreFilter is a list of plugins that should be invoked at "PreFilter" extension point of the scheduling framework.
PreFilter PluginSet
// Filter is a list of plugins that should be invoked when filtering out nodes that cannot run the Pod.
Filter PluginSet
// PostFilter is a list of plugins that are invoked after filtering phase, but only when no feasible nodes were found for the pod.
PostFilter PluginSet
// PreScore is a list of plugins that are invoked before scoring.
PreScore PluginSet
// Score is a list of plugins that should be invoked when ranking nodes that have passed the filtering phase.
Score PluginSet
// Reserve is a list of plugins invoked when reserving/unreserving resources
// after a node is assigned to run the pod.
Reserve PluginSet
// Permit is a list of plugins that control binding of a Pod. These plugins can prevent or delay binding of a Pod.
Permit PluginSet
// PreBind is a list of plugins that should be invoked before a pod is bound.
PreBind PluginSet
// Bind is a list of plugins that should be invoked at "Bind" extension point of the scheduling framework.
// The scheduler call these plugins in order. Scheduler skips the rest of these plugins as soon as one returns success.
Bind PluginSet
// PostBind is a list of plugins that should be invoked after a pod is successfully bound.
PostBind PluginSet
// MultiPoint is a simplified config field for enabling plugins for all valid extension points
MultiPoint PluginSet
}
type PluginSet struct {
// Enabled指定除了默认插件之外还应启用的插件。这些是在默认插件之后调用的,并且按照此处指定的相同顺序
Enabled []Plugin
// Disabled指定应禁用的默认插件。当需要禁用所有默认插件时,只包含一个“*”的数组应该be provided.
Disabled []Plugin
}
type Plugin struct {
Name string // 插件名
Weight int32 // 权重,仅在评分时使用
}
执行时。插件包括多个扩展点,当指定时特定扩展点的插件列表是唯一启用的插件。如果从配置中省略了一个扩展点,那么该扩展点将使用默认的插件集。
启用的插件按此处指定的顺序调用,在默认插件之后调用。如果需要在默认插件之前调用它们,则必须在此处按所需顺序禁用并重新启用默认插件。
PreEnqueue // 进入调度队列前调用
↓
QueueSort // 在 scheduler queue 里对Pod排序调用
↓
PreFilter -> Filter -> PostFilter // 其中 Filter 是在筛选出无法运行Pod的节点时调用
↓ // PostFilter 是在过滤阶段后但找不到pod的可行节点时调用
PreScore -> Score
↓
Reserve
↓
Permit
↓
PreBind -> Bind -> PostBind
↓
MultiPoint
对于这些插件列表它们每个都有对应的 extension points ,也只有在这些对应的扩展点时它们才有机会被调用。
PreEnqueue 进入调度队列前调用
QueueSort 在 scheduler queue 里对Pod排序调用
PreFilter 在 scheduling framework 的 PreFilter 扩展点调用
Filter 筛选出无法运行 Pod 的 node 时调用
PostFilter 过滤阶段后但找不到 pod 的可行 node 时调用, 与 Filter 的扩展点不一样
PreScore 评分前调用
Score已通过筛选阶段的节点进行排名时调用
Reserve 在分配 node 运行pod后, reserving/unreserving 服务资源时调用
Permit 用于控制Pod的绑定,这些插件可以 阻止 或 延迟 Pod的绑定
PreBind 绑定pod之前调用
Bind 在 scheduling framework. 的 _Bind_扩展点调用
PostBind 在pod成功绑定后调用
MultiPoint 在所有有效的扩展点被调用,也就是说这个插件是对全局扩展点有效的。
下面我们将会用到PreQueue 这个插件列表
总结
profiles 字段是一个 scheduler 切片,而每个 scheduler 对应一些插件,这些插件又按执行扩展点的先后顺序进行了分组 Plugins Set, 组里的插件也只有在他们自己的 extension points 才会被调用,对于 MultiPoint 会在所有有效的 extension points 被调用。
现在我们再回到初始化调度器的主流程。
if options.applyDefaultProfile {
// 调度器配置,很重要,特别是 Profiles 和 Extenders 字段
// 对象转换,将 versiondCfg 转为 cfg
var versionedCfg configv1.KubeSchedulerConfiguration
scheme.Scheme.Default(&versionedCfg)
cfg := schedulerapi.KubeSchedulerConfiguration{}
if err := scheme.Scheme.Convert(&versionedCfg, &cfg, nil); err != nil {
return nil, err
}
// 通过指定 "scheduler name" profile,可以用来控制Pod的调度行为,如何为空则默认使用 "default-scheduler" profile
options.profiles = cfg.Profiles
}
根据是否启默认配置文件来初始化 defaultSchedulerOptions.Options 字段,通过 scheduler_name 来控制Pod调度行为(其实是通过scheduler_name 的 Plugins 实现对Pod的调度控制 )。
这里 KubeSchedulerConfiguration 结构体
// KubeSchedulerConfiguration configures a scheduler
type KubeSchedulerConfiguration struct {
...
// Profiles are scheduling profiles that kube-scheduler supports. Pods can
// choose to be scheduled under a particular profile by setting its associated
// scheduler name. Pods that don't specify any scheduler name are scheduled
// with the "default-scheduler" profile, if present here.
// +listType=map
// +listMapKey=schedulerName
Profiles []KubeSchedulerProfile `json:"profiles,omitempty"`
// Extenders are the list of scheduler extenders, each holding the values of how to communicate
// with the extender. These extenders are shared by all scheduler profiles.
// +listType=set
Extenders []Extender `json:"extenders,omitempty"`
}
其配置内容大概为
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
leaderElection:
leaderElect: false
leaseDuration: 15s
renewDeadline: 10s
resourceName: sample-scheduler
resourceNamespace: kube-system
retryPeriod: 2s
profiles:
- schedulerName: my-custom-scheduler
plugins:
filter:
enabled:
- name: sample
插件构建器注册表
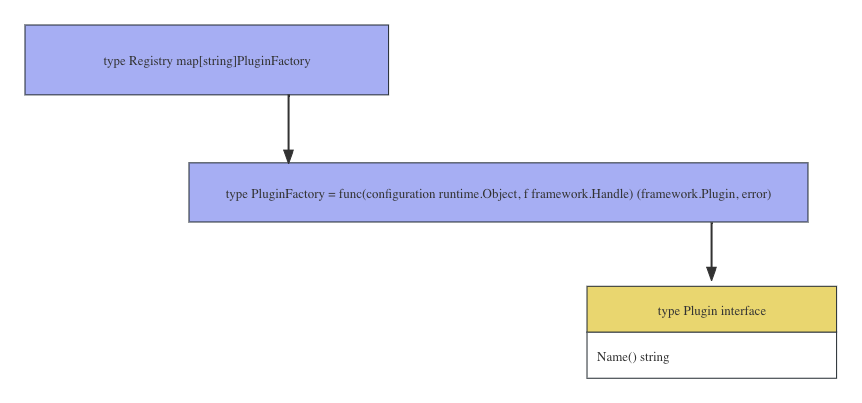
注册所有内置插件,registry 的数据结构为 map[string]PluginFactory
// 插件构建函数注册表,
// 注册表是所有可用插件的集合,framework 使用注册表来启用和初始化配置的插件。在初始化框架之前,所有插件都必须在注册表中。
registry := frameworkplugins.NewInTreeRegistry()
if err := registry.Merge(options.frameworkOutOfTreeRegistry); err != nil {
return nil, err
}
调用 frameworkplugins.NewInTreeRegistry() 实现 in-tree 插件的注册,也可通过 [WithFrameworkOutOfTreeRegistry()](https://github.com/kubernetes/kubernetes/blob/v1.27.3/cmd/kube-scheduler/app/server.go#L347) 选项函数注册外部插件
func NewInTreeRegistry() runtime.Registry {
fts := plfeature.Features{
EnableDynamicResourceAllocation: feature.DefaultFeatureGate.Enabled(features.DynamicResourceAllocation),
EnableReadWriteOncePod: feature.DefaultFeatureGate.Enabled(features.ReadWriteOncePod),
EnableVolumeCapacityPriority: feature.DefaultFeatureGate.Enabled(features.VolumeCapacityPriority),
EnableMinDomainsInPodTopologySpread: feature.DefaultFeatureGate.Enabled(features.MinDomainsInPodTopologySpread),
EnableNodeInclusionPolicyInPodTopologySpread: feature.DefaultFeatureGate.Enabled(features.NodeInclusionPolicyInPodTopologySpread),
EnableMatchLabelKeysInPodTopologySpread: feature.DefaultFeatureGate.Enabled(features.MatchLabelKeysInPodTopologySpread),
EnablePodSchedulingReadiness: feature.DefaultFeatureGate.Enabled(features.PodSchedulingReadiness),
EnablePodDisruptionConditions: feature.DefaultFeatureGate.Enabled(features.PodDisruptionConditions),
EnableInPlacePodVerticalScaling: feature.DefaultFeatureGate.Enabled(features.InPlacePodVerticalScaling),
}
// 所有内置插件
registry := runtime.Registry{
dynamicresources.Name: runtime.FactoryAdapter(fts, dynamicresources.New),
selectorspread.Name: selectorspread.New,
imagelocality.Name: imagelocality.New,
tainttoleration.Name: tainttoleration.New,
nodename.Name: nodename.New,
nodeports.Name: nodeports.New,
nodeaffinity.Name: nodeaffinity.New,
podtopologyspread.Name: runtime.FactoryAdapter(fts, podtopologyspread.New),
nodeunschedulable.Name: nodeunschedulable.New,
noderesources.Name: runtime.FactoryAdapter(fts, noderesources.NewFit),
noderesources.BalancedAllocationName: runtime.FactoryAdapter(fts, noderesources.NewBalancedAllocation),
volumebinding.Name: runtime.FactoryAdapter(fts, volumebinding.New),
volumerestrictions.Name: runtime.FactoryAdapter(fts, volumerestrictions.New),
volumezone.Name: volumezone.New,
nodevolumelimits.CSIName: runtime.FactoryAdapter(fts, nodevolumelimits.NewCSI),
nodevolumelimits.EBSName: runtime.FactoryAdapter(fts, nodevolumelimits.NewEBS),
nodevolumelimits.GCEPDName: runtime.FactoryAdapter(fts, nodevolumelimits.NewGCEPD),
nodevolumelimits.AzureDiskName: runtime.FactoryAdapter(fts, nodevolumelimits.NewAzureDisk),
nodevolumelimits.CinderName: runtime.FactoryAdapter(fts, nodevolumelimits.NewCinder),
interpodaffinity.Name: interpodaffinity.New,
queuesort.Name: queuesort.New,
defaultbinder.Name: defaultbinder.New,
defaultpreemption.Name: runtime.FactoryAdapter(fts, defaultpreemption.New),
schedulinggates.Name: runtime.FactoryAdapter(fts, schedulinggates.New),
}
return registry
}
通过插件器可以实现的功能有实现 注册插件,取消注册插件 和 合并插件
type Registry map[string]PluginFactory
func (r Registry) Register(name string, factory PluginFactory) error {}
func (r Registry) Unregister(name string) error {}
func (r Registry) Merge(in Registry) error {}
extenders 扩展器构建
扩展器是外部进程影响Kubernetes做出的调度决策的接口,这通常是不由Kubernetes直接管理的资源所需要的。
// pkg/scheduler/apis/config/types.go#L261-L301
type Extender struct {
URLPrefix string
FilterVerb string
PreemptVerb string
PrioritizeVerb string
Weight int64
BindVerb string
EnableHTTPS bool
TLSConfig *ExtenderTLSConfig
HTTPTimeout v1.Duration
NodeCacheCapable bool
ManagedResources []ExtenderManagedResource
Ignorable bool
}
保存用于与扩展器通信的参数,如果谓词未指定/为空,则假定扩展程序选择不提供该扩展。
extenders, err := buildExtenders(options.extenders, options.profiles)
对于扩展器的构建需要 options.extenders 参数, 其是扩展器参数配置 它返回的是一个 []framework.Extender 数据类型。我们看一下其具体实现
func buildExtenders(extenders []schedulerapi.Extender, profiles []schedulerapi.KubeSchedulerProfile) ([]framework.Extender, error) {
var fExtenders []framework.Extender
if len(extenders) == 0 {
return nil, nil
}
var ignoredExtendedResources []string
var ignorableExtenders []framework.Extender
for i := range extenders {
// 根据每个扩展器参数配置创建一个 httpClient 对象的wrapper
extender, err := NewHTTPExtender(&extenders[i])
if err != nil {
return nil, err
}
// 在调度时,当扩展程序返回错误或无法访问时,扩展器是否被忽略
if !extender.IsIgnorable() {
fExtenders = append(fExtenders, extender)
} else {
ignorableExtenders = append(ignorableExtenders, extender)
}
for _, r := range extenders[i].ManagedResources {
if r.IgnoredByScheduler {
ignoredExtendedResources = append(ignoredExtendedResources, r.Name)
}
}
}
// 将允许忽略的扩展器放在最后面
fExtenders = append(fExtenders, ignorableExtenders...)
// If there are any extended resources found from the Extenders, append them to the pluginConfig for each profile.
// This should only have an effect on ComponentConfig, where it is possible to configure Extenders and
// plugin args (and in which case the extender ignored resources take precedence).
if len(ignoredExtendedResources) == 0 {
return fExtenders, nil
}
// 更新每个scheduler name 中插件 noderesources.Name 的参数(prof.PluginConfig[k].Args.IgnoredResources)
for i := range profiles {
prof := &profiles[i]
var found = false
for k := range prof.PluginConfig {
if prof.PluginConfig[k].Name == noderesources.Name {
// Update the existing args
pc := &prof.PluginConfig[k]
args, ok := pc.Args.(*schedulerapi.NodeResourcesFitArgs)
if !ok {
return nil, fmt.Errorf("want args to be of type NodeResourcesFitArgs, got %T", pc.Args)
}
// 允许出错被忽略的扩展器
args.IgnoredResources = ignoredExtendedResources
found = true
break
}
}
if !found {
return nil, fmt.Errorf("can't find NodeResourcesFitArgs in plugin config")
}
}
return fExtenders, nil
}
这里 profiles[i].PluginConfig[i].args 字段类型对应的是 NodeResourcesFitArgs,它是一个 []string 类型
type NodeResourcesFitArgs struct {
v1.TypeMeta
IgnoredResources []string
IgnoredResourceGroups []string
ScoringStrategy *ScoringStrategy
}
创建 podLister 和 nodeLister
podLister := informerFactory.Core().V1().Pods().Lister()
nodeLister := informerFactory.Core().V1().Nodes().Lister()
通过 informetFactory 工作模式创建 podLister 和 nodeLister, 可以用来获取所有对象资源列表。如 posLister 可以用来获取所有 Pod 列表, nodeLister 则可以获取所有 node 列表。
创建scheduler.Profiles
这一块是 sched.Profiles 字段,涉及到 Framework ,先上一张 Framework 结构体关系图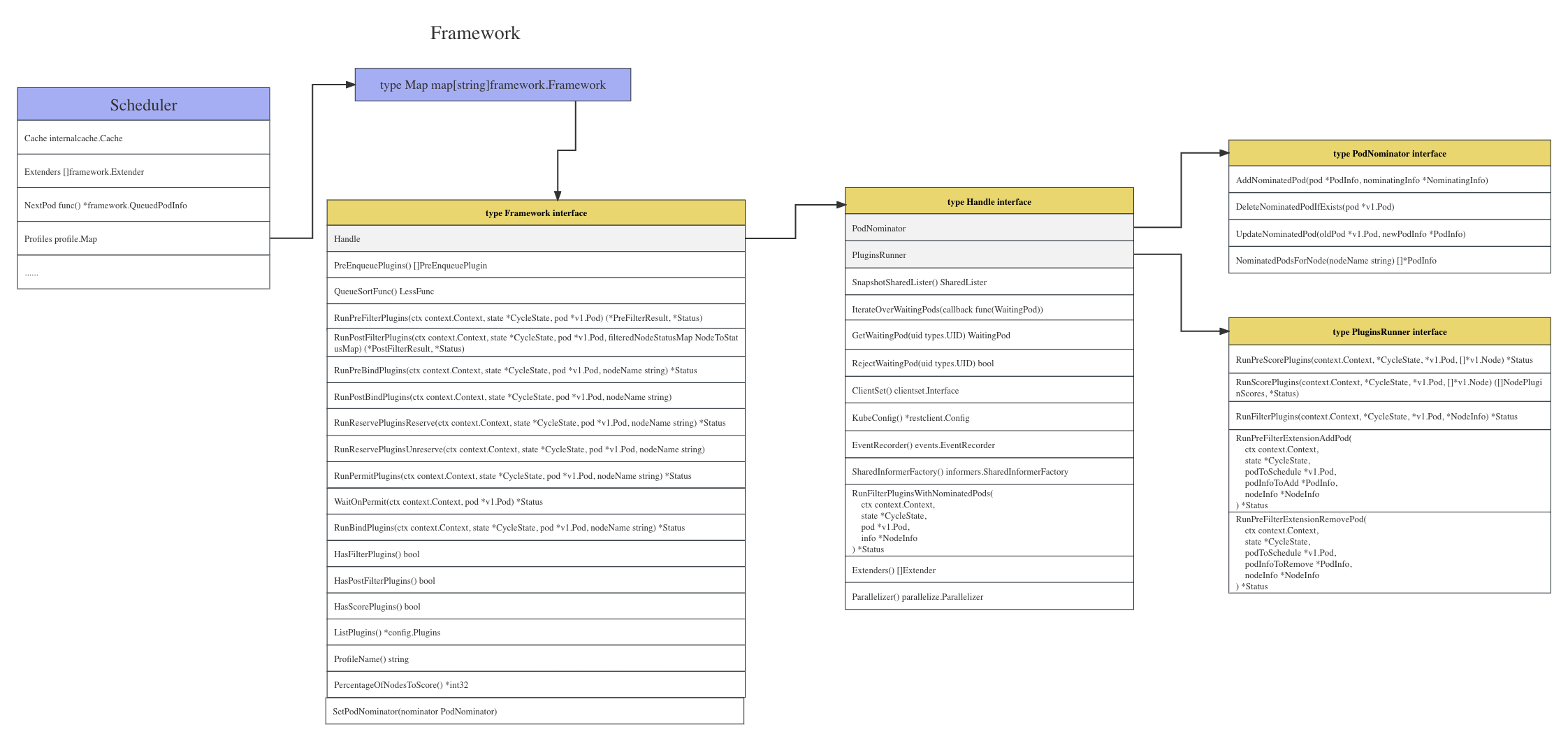
可以看到好多执行插件的方法,后面打一个节点打分就是由 Framework 来执行的,运行的 RunScorePlugins() 方法。
对于接口 Framework 的实现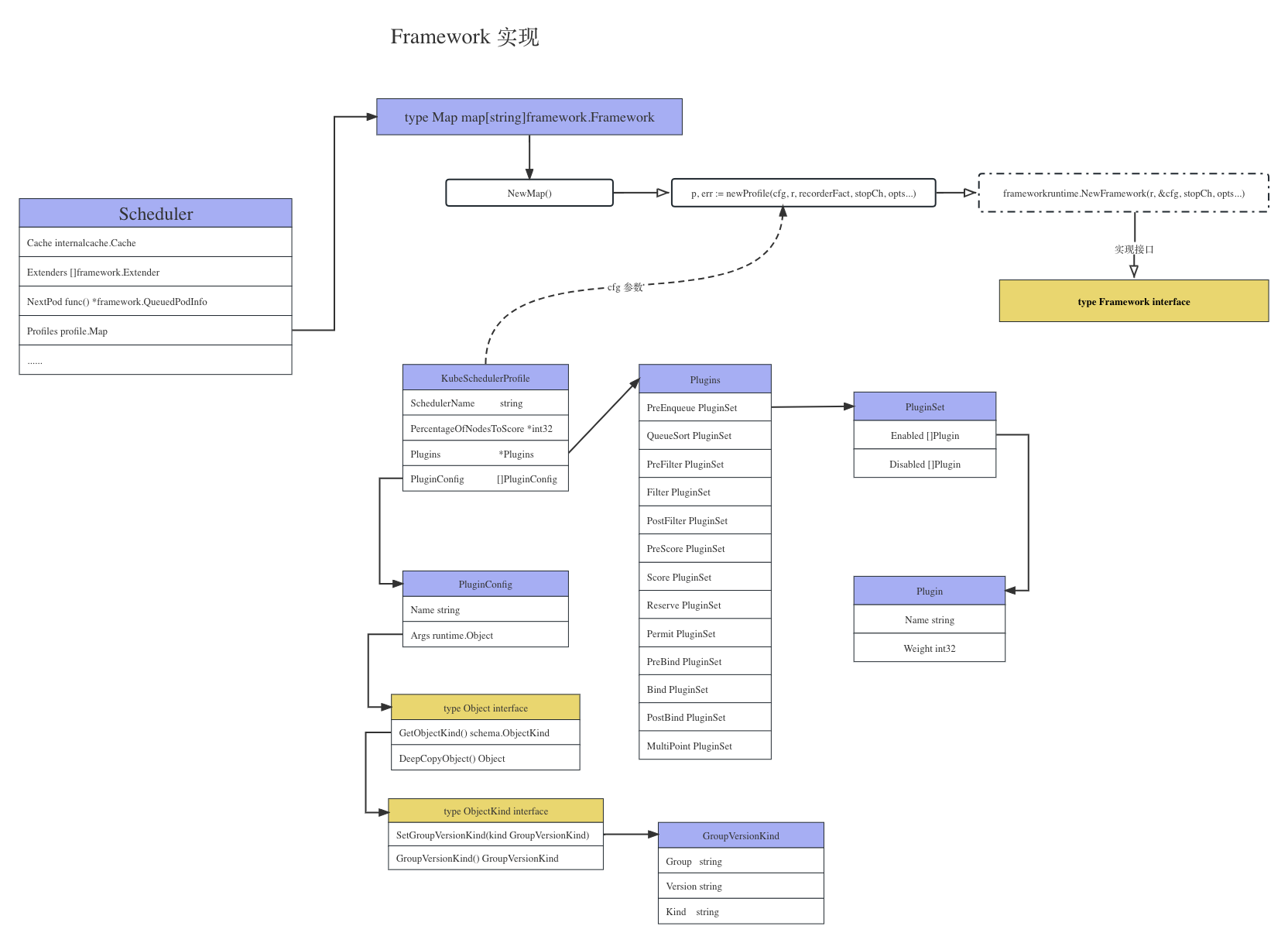
这里根据配置文件生成相应的 Framework。
// 节点快照
snapshot := internalcache.NewEmptySnapshot()
// clusterEvent 集合
clusterEventMap := make(map[framework.ClusterEvent]sets.String)
metricsRecorder := metrics.NewMetricsAsyncRecorder(1000, time.Second, stopCh)
// 根据给出的profiles配置文件 生成对应的 frameworks,(Map类型,格式为 SchedulerName:Framework)
// 而每一个 frameworks 都会对自己的 plugins 集进行管理,然后在调度上下文中的各种埋点执行插件
// registry 其实是 frameworkImpl.registry 字段
profiles, err := profile.NewMap(
// 调度器配置
options.profiles,
// 插件构建器注册表
registry,
recorderFactory, stopCh,
// 下面的全是 Options functions 模式,可任意数量
// componentConfig 版本号
frameworkruntime.WithComponentConfigVersion(options.componentConfigVersion),
// api server 的客户端,一般通过读取 $HOME/.kube/config 文件创建
frameworkruntime.WithClientSet(client),
// kubeConfig,一般是 $HOME/kube/config 文件
frameworkruntime.WithKubeConfig(options.kubeConfig),
// SharedInformerFactory
frameworkruntime.WithInformerFactory(informerFactory),
// 设置 SharedLister,用途?
frameworkruntime.WithSnapshotSharedLister(snapshot),
// 回调函数 frameworkruntime.WithCaptureProfile(frameworkruntime.CaptureProfile(options.frameworkCapturer)),
// 设置一个 clusterEvent 的 Set 类型
frameworkruntime.WithClusterEventMap(clusterEventMap),
// 设置并行调度数量,默认为16
frameworkruntime.WithParallelism(int(options.parallelism)),
// 设置外部扩展器
frameworkruntime.WithExtenders(extenders),
// 指标记录器
frameworkruntime.WithMetricsRecorder(metricsRecorder),
)
先是通过 Options functions 的方式指定了多个参数,其函数 profile.NewMap()实现
// NewMap builds the frameworks given by the configuration, indexed by name.
func NewMap(cfgs []config.KubeSchedulerProfile, r frameworkruntime.Registry, recorderFact RecorderFactory,
stopCh <-chan struct{}, opts ...frameworkruntime.Option) (Map, error) {
m := make(Map)
v := cfgValidator{m: m}
for _, cfg := range cfgs {
// 根据给的配置构建 Framework
p, err := newProfile(cfg, r, recorderFact, stopCh, opts...)
if err != nil {
return nil, fmt.Errorf("creating profile for scheduler name %s: %v", cfg.SchedulerName, err)
}
if err := v.validate(cfg, p); err != nil {
return nil, err
}
// scheduler name 为key, 以 Framework 为value
m[cfg.SchedulerName] = p
}
return m, nil
}
根据每个 profile 调用 newProfile() 生成对应的 frameworkImpl,其实现了 Framework 接口,这里真正的实现位于函数 NewFramework(), 这里不做介绍。
type Framework interface {
// 插件需要的数据和一些工具,在插件初始化的时候通过 pluginFactory 传入,见 NewInTreeRegistry() 函数
Handle
// 返回注册过的 preEnqueue 插件列表
PreEnqueuePlugins() []PreEnqueuePlugin
// 获取 pod 在队列中的排序函数
QueueSortFunc() LessFunc
// PreFilter 插件
RunPreFilterPlugins(ctx context.Context, state *CycleState, pod *v1.Pod) (*PreFilterResult, *Status)
// PostFilter
RunPostFilterPlugins(ctx context.Context, state *CycleState, pod *v1.Pod, filteredNodeStatusMap NodeToStatusMap) (*PostFilterResult, *Status)
// PreBind
RunPreBindPlugins(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string) *Status
// PostBind
RunPostBindPlugins(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string)
// Reserve
RunReservePluginsReserve(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string) *Status
// Unreserve
RunReservePluginsUnreserve(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string)
// Permit
RunPermitPlugins(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string) *Status
// 如果pod处于waiting状态,则将处于block状态,直到pod被 rejected 或 allowed
WaitOnPermit(ctx context.Context, pod *v1.Pod) *Status
// Bind
RunBindPlugins(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string) *Status
// 是否定义了 Filter 插件
HasFilterPlugins() bool
// 是否定义了 PostFilter 插件
HasPostFilterPlugins() bool
// 是否定义了 Score
HasScorePlugins() bool
// 返回定义的plugins 对象
ListPlugins() *config.Plugins
ProfileName() string
PercentageOfNodesToScore() *int32
// 设置 SetPodNominator
SetPodNominator(nominator PodNominator)
}
Framework 通过 scheduling framework 管理着一些插件。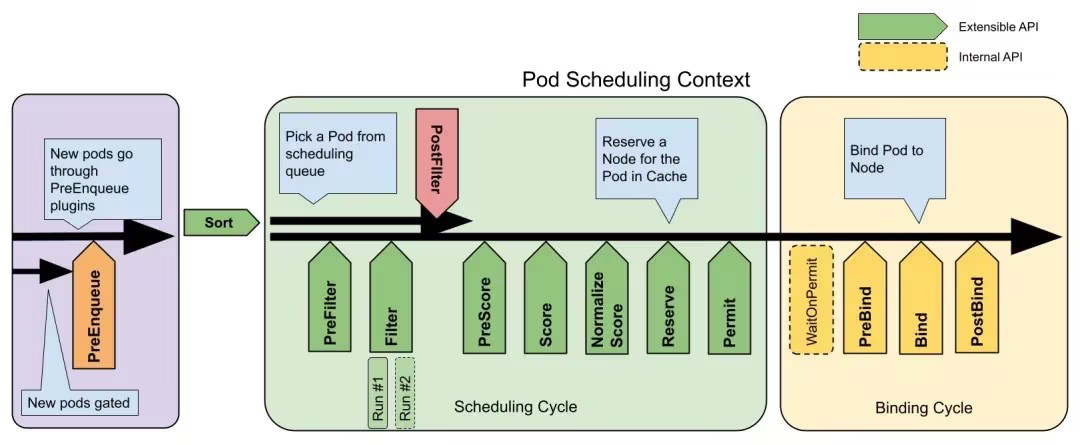
这些插件可以在调度上下文中的指定 points 被调用,这里共将调度上下分成了三个阶段,每个阶段都会执行对应的所有插件。
调度队列创建
首先遍历 profiles 获取其对应的已注册好的 PreQueuePlugin 插件,这些插件是在将Pods添加到 activeQ 之前调用。
preEnqueuePluginMap := make(map[string][]framework.PreEnqueuePlugin)
for profileName, profile := range profiles {
preEnqueuePluginMap[profileName] = profile.PreEnqueuePlugins()
}
然后创建一个优先队列 sched.SchedulingQueue。
// 初始化一个优先队列作为调度队列 sched.SchedulingQueue
podQueue := internalqueue.NewSchedulingQueue(
// 获取profile 设置的调度队列Pod里的Pod排序函数,这里指定获取第 options.profiles[0]个profile
profiles[options.profiles[0].SchedulerName].QueueSortFunc(),
// sharedInformerFactory
informerFactory,
// 设置 pod 的 Initial阶段的 Backoff 的持续时间
internalqueue.WithPodInitialBackoffDuration(time.Duration(options.podInitialBackoffSeconds)*time.Second),
// 最大backoff持续时间 internalqueue.WithPodMaxBackoffDuration(time.Duration(options.podMaxBackoffSeconds)*time.Second),
// 设置podLister
internalqueue.WithPodLister(podLister),
// 设置 clusterEvent
internalqueue.WithClusterEventMap(clusterEventMap),
// 一个pod在 unschedulablePods 停留的最长时间
internalqueue.WithPodMaxInUnschedulablePodsDuration(options.podMaxInUnschedulablePodsDuration),
// preEnqueuePluginMap 插件注册
internalqueue.WithPreEnqueuePluginMap(preEnqueuePluginMap),
// 指标相关
internalqueue.WithPluginMetricsSamplePercent(pluginMetricsSamplePercent),
internalqueue.WithMetricsRecorder(*metricsRecorder),
)
然后从原来的 profiles 中读取一些配置,如 preEnqueuePlugin 、 Pod 在队列里的排序函数 QueueSortFunc() 作为调用函数 internalqueue.NewSchedulingQueue() 的入参。函数实现
// pkg/scheduler/internal/queue/scheduling_queue.go#L291-L330
// NewPriorityQueue creates a PriorityQueue object.
func NewPriorityQueue(
lessFn framework.LessFunc,
informerFactory informers.SharedInformerFactory,
opts ...Option,
) *PriorityQueue {
options := defaultPriorityQueueOptions
if options.podLister == nil {
options.podLister = informerFactory.Core().V1().Pods().Lister()
}
for _, opt := range opts {
opt(&options)
}
// pod 排序
comp := func(podInfo1, podInfo2 interface{}) bool {
pInfo1 := podInfo1.(*framework.QueuedPodInfo)
pInfo2 := podInfo2.(*framework.QueuedPodInfo)
return lessFn(pInfo1, pInfo2)
}
// 初始化优先队列
pq := &PriorityQueue{
// 存储维护pod与其运行在哪个节点关系
nominator: newPodNominator(options.podLister),
clock: options.clock,
stop: make(chan struct{}),
podInitialBackoffDuration: options.podInitialBackoffDuration,
podMaxBackoffDuration: options.podMaxBackoffDuration,
// 一个pod在 unschedulablePods 停留的最长时间
podMaxInUnschedulablePodsDuration: options.podMaxInUnschedulablePodsDuration,
activeQ: heap.NewWithRecorder(podInfoKeyFunc, comp, metrics.NewActivePodsRecorder()),
// 包含已尝试并确定为不可调度的pod, 其实是一个map类型,对应 podInfoMap map[string]*framework.QueuedPodInfo
unschedulablePods: newUnschedulablePods(metrics.NewUnschedulablePodsRecorder(), metrics.NewGatedPodsRecorder()),
moveRequestCycle: -1,
// clusterEvent
clusterEventMap: options.clusterEventMap,
// preEnqueuePlugin
preEnqueuePluginMap: options.preEnqueuePluginMap,
metricsRecorder: options.metricsRecorder,
pluginMetricsSamplePercent: options.pluginMetricsSamplePercent,
}
pq.cond.L = &pq.lock
pq.podBackoffQ = heap.NewWithRecorder(podInfoKeyFunc, pq.podsCompareBackoffCompleted, metrics.NewBackoffPodsRecorder())
pq.nsLister = informerFactory.Core().V1().Namespaces().Lister()
return pq
}
几个重要的点已在代码里进行了注释,下面我们重点看理解队列这个概念。
我们以这里的 PriorityQueue为例,其实现了 SchedulingQueue 接口。PriorityQueue 队列 head 的 Pod 具有最高优先级,它有两个 sub queue 和一个可选的data structure:
activeQ :子队列,持有即将等待被调度的 Pod,将会根据其优先级和其他配置信息来排队等待调度程序对其进行分配。
backoffQ :子队列,双称为退避队列。 持有从 unschedulablePods 中移走的Pod, 并将在其 backoff periods 退避期结束时移动到activeQ 队列。Pod 在退避队列中等待并定期尝试进行重新调度。重新调度的频率会按照一个指数级的算法定时增加,从而充分探索可用的资源,直到找到可以分配给该 Pod 的节点。
unschedulablePods :不可调度Pod的列表,也可以将其理解为不可调度队列 unschedulable queue 。持有已尝试进行调度且当前确定为不可调度的Pod。
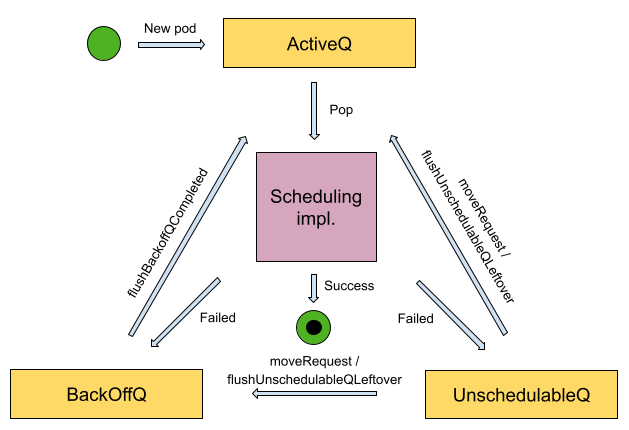
三个队列都是 Kubernetes 调度器的三个基本导向队列,调度器将使用其内置策略和其他算法来对它们进行维护和管理。
队列机制将通过调用 Run() 创建两个gorouteine进行从 podBackoffQ 到 activeQ 的 Pod流转,这一点下面会介绍。
我们看一下队列常用的一些方法
// 从 activeQ 队列中以阻塞的方式获取一个Pod,会将增加 scheduling cycle 的值
func (p *PriorityQueue) Pop() (*framework.QueuedPodInfo, error){}
// 更新一个队列,分两种情况:
// 不存在:如果 pod 是全新的,则直接添加到 activeQ 队列
// 已存在:如果 pod 在 activeQ 或 backoffQ 队列中已存在,则直接更新;否则,如果pod以可调度的方式更新,它将从不可调度队列 unschedulablePods 中删除,并将更新后的pod添加到 activeQ 中(如修正了原来pod的错误后恢复正常)。
func (p *PriorityQueue) Update(oldPod, newPod *v1.Pod) error {}
// 从三个队列中删除 pod
func (p *PriorityQueue) Delete(pod *v1.Pod) error {}
// 将pod添加到 activeQ 队列,如果添加的pod已经在activeQ、backoffQ或unschedulablePods 存在,则不会有任何效果
func (p *PriorityQueue) Add(pod *v1.Pod) error {)
// 将给定的一组 Pod 从 unschedulablePods 或 backoffQ 队列中移动到 activeQ 队列中,前提是这些 Pod 正在 unschedulablePods 或 backoffQ 队列中
func (p *PriorityQueue) Activate(pods map[string]*v1.Pod) {}
SetPodNominator
// 根据 profiles 设置PodNominator
for _, fwk := range profiles {
fwk.SetPodNominator(podQueue)
}
指定每个 profile 对应的 Framework ,对于Pod是从 podQueue 队列中获取。
调度缓存
// 设置缓存,此时缓存服务自动处于运行状态
schedulerCache := internalcache.New(durationToExpireAssumedPod, stopEverything)
// Setup cache debugger.
debugger := cachedebugger.New(nodeLister, podLister, schedulerCache, podQueue)
debugger.ListenForSignal(stopEverything)
调用函数 internalcache.New(durationToExpireAssumedPod, stopEverything) 生成一个 goroutine 来过期的 Pod, 第一个参数为 ttl, 表示Pod的过期时间,如果为 则表示永不过期,这里`durationToExpireAssumedPod` 的值为;第二次参数是pod停止信号。
疑问:为什么要添加一层 Cache 呢?
创建 scheduler 对象
sched := &Scheduler{
Cache: schedulerCache, // 缓存
client: client, // api server 客户端
nodeInfoSnapshot: snapshot, // node 快照信息
percentageOfNodesToScore: options.percentageOfNodesToScore,
Extenders: extenders, // 扩展器
// 获取Pod函数,对应的是优先队列里的 Pop() 方法
NextPod: internalqueue.MakeNextPodFunc(podQueue),
StopEverything: stopEverything,
SchedulingQueue: podQueue, // 队列
Profiles: profiles, // 配置文件
}
sched.applyDefaultHandlers()
addAllEventHandlers(sched, informerFactory, dynInformerFactory, unionedGVKs(clusterEventMap))
调用 sched.applyDefaultHandlers() 设置调度Pod函数 和 调度失败处理函数。
func (s *Scheduler) applyDefaultHandlers() {
s.SchedulePod = s.schedulePod
s.FailureHandler = s.handleSchedulingFailure
}
这里 s.schedulePod() 作为调度实现函数,是我们关注的重点中的重点。
调度器执行
上面做了好么多工作,只是为了调度器能够执行。对于调度器的执行入口为
// cmd/kube-scheduler/app/server.go#L243
// Run executes the scheduler based on the given configuration. It only returns on error or when context is done.
func Run(ctx context.Context, cc *schedulerserverconfig.CompletedConfig, sched *scheduler.Scheduler) error {
...
// 调度器执行
sched.Run(ctx)
}
这里调用了sched.Run() 函数真正将服务运行起来,我们看一下它做了哪些事。
// pkg/scheduler/scheduler.go#L337-L391
// Run begins watching and scheduling. It starts scheduling and blocked until the context is done.
func (sched *Scheduler) Run(ctx context.Context) {
// 1. 优先队列运行
sched.SchedulingQueue.Run()
// We need to start scheduleOne loop in a dedicated goroutine,
// because scheduleOne function hangs on getting the next item
// from the SchedulingQueue.
// If there are no new pods to schedule, it will be hanging there
// and if done in this goroutine it will be blocking closing
// SchedulingQueue, in effect causing a deadlock on shutdown.
// 2. 在单独的goroutine里以 loop 方式调度Pod
go wait.UntilWithContext(ctx, sched.scheduleOne, 0)
// 调度服务结束
<-ctx.Done()
sched.SchedulingQueue.Close()
}
这里做了两件事:
- 将优先队列服务运行起来
- 以 loop 的方式调用
sched.scheduleOne()调度Pod,一次调度一个Pod。
对于Pod的调度,这里指定了 UntilWithContext(ctx context.Context, f func(context.Context), period time.Duration) 函数的 period 参数为 ``,表示是在一个 loop 中执行 sched.scheduleOne()函数。
调度时会从 SchedulingQueue 优先队列里获取一个Pod;如果没有新的Pod要调度,它将一直阻塞。
下面我们看一下这两块的实现逻辑。
优先队列
首先通过调用 sched.SchedulingQueue.Run()启用优先队列服务。
func (p *PriorityQueue) Run() {
go wait.Until(p.flushBackoffQCompleted, 1.0*time.Second, p.stop)
go wait.Until(p.flushUnschedulablePodsLeftover, 30*time.Second, p.stop)
}
这里就干两件事:
- 每
10秒执行一个p.flushBackoffQCompleted()函数,将所有已完成的Pod从backoffQ队列移动到activeQ队列 - 每
30秒执行一次flushUnschedulablePodsLeftover()函数,将所有停留在unschedulablePods中时间超出 podMaxInUnschedulablePodsDuration 的Pod移动到backoffQ或activeQ队列
这两件事全部在单独的 goroutine 里以 loop 的方式定时执行,下面我们看一下它们两者的实现。
flushBackoffQCompleted()
将所有已完成的Pod从 backoffQ 移动到 activeQ 队列
func (p *PriorityQueue) flushBackoffQCompleted() {
p.lock.Lock()
defer p.lock.Unlock()
activated := false
for {
// 获取队列头部元素,但不从队列里删除
rawPodInfo := p.podBackoffQ.Peek()
if rawPodInfo == nil {
break
}
pInfo := rawPodInfo.(*framework.QueuedPodInfo)
pod := pInfo.Pod
if p.isPodBackingoff(pInfo) {
break
}
// 删除获取队列头部元素
_, err := p.podBackoffQ.Pop()
if err != nil {
klog.ErrorS(err, "Unable to pop pod from backoff queue despite backoff completion", "pod", klog.KObj(pod))
break
}
// 移入 activeQ 队列
if added, _ := p.addToActiveQ(pInfo); added {
activated = true
}
}
if activated {
p.cond.Broadcast()
}
}
加入 activeQ 函数实现
func (p *PriorityQueue) addToActiveQ(pInfo *framework.QueuedPodInfo) (bool, error) {
// 执行插件 runPreEnqueuePlugins
pInfo.Gated = !p.runPreEnqueuePlugins(context.Background(), pInfo)
if pInfo.Gated {
// Add the Pod to unschedulablePods if it's not passing PreEnqueuePlugins.
p.unschedulablePods.addOrUpdate(pInfo)
return false, nil
}
// 加入队列,如果已在队列则直接更新(什么情况下会在activeQ队列存在?)
if err := p.activeQ.Add(pInfo); err != nil {
klog.ErrorS(err, "Error adding pod to the active queue", "pod", klog.KObj(pInfo.Pod))
return false, err
}
return true, nil
}
flushUnschedulablePodsLeftover()
将所有停留在 unschedulablePods 中时间超出 podMaxInUnschedulablePodsDuration 的Pod移动到 backoffQ 或 activeQ 队列
func (p *PriorityQueue) flushUnschedulablePodsLeftover() {
var podsToMove []*framework.QueuedPodInfo
currentTime := p.clock.Now()
for _, pInfo := range p.unschedulablePods.podInfoMap {
lastScheduleTime := pInfo.Timestamp
if currentTime.Sub(lastScheduleTime) > p.podMaxInUnschedulablePodsDuration {
podsToMove = append(podsToMove, pInfo)
}
}
// 移入activeQ 或 BackoffQueue
if len(podsToMove) > 0 {
p.movePodsToActiveOrBackoffQueue(podsToMove, UnschedulableTimeout)
}
}
// 将 Pod 移动到 activeQ 或 backoffQ
func (p *PriorityQueue) movePodsToActiveOrBackoffQueue(podInfoList []*framework.QueuedPodInfo, event framework.ClusterEvent) {
activated := false
for _, pInfo := range podInfoList {
if len(pInfo.UnschedulablePlugins) != 0 && !p.podMatchesEvent(pInfo, event) {
continue
}
pod := pInfo.Pod
if p.isPodBackingoff(pInfo) {
if err := p.podBackoffQ.Add(pInfo); err != nil {
klog.ErrorS(err, "Error adding pod to the backoff queue", "pod", klog.KObj(pod))
} else {
klog.V(5).InfoS("Pod moved to an internal scheduling queue", "pod", klog.KObj(pInfo.Pod), "event", event, "queue", backoffQName)
metrics.SchedulerQueueIncomingPods.WithLabelValues("backoff", event.Label).Inc()
// 从 unschedulablePods 里删除Pod
p.unschedulablePods.delete(pod, pInfo.Gated)
}
} else {
gated := pInfo.Gated
// 添加到 activeQ 队列,并从 unschedulablePods 中将其删除
if added, _ := p.addToActiveQ(pInfo); added {
klog.V(5).InfoS("Pod moved to an internal scheduling queue", "pod", klog.KObj(pInfo.Pod), "event", event, "queue", activeQName)
activated = true
metrics.SchedulerQueueIncomingPods.WithLabelValues("active", event.Label).Inc()
p.unschedulablePods.delete(pod, gated)
}
}
}
p.moveRequestCycle = p.schedulingCycle
if activated {
p.cond.Broadcast()
}
}
下面我们先看一下调度Pod的逻辑,最后再看队列相关的两个函数
调度Pod
scheduleOne() 函数实现了一个 Pod 的整个调度过程,整个步骤分为:
- 从优先队列里获取一个待调度的 Pod
- 根据Pod的信息,获取指定的
Framework - 筛选出一个可能被调度的 Node,如果有
>1个节点的话,还需要对每个节点进行评分,找出评分最高的Node - 以
异步的方式绑定 Pod 与 Node
获取待调度的Pod
func (sched *Scheduler) scheduleOne(ctx context.Context) {
// 1. 获取一个 Pod, 如果为 nil 则直接返回取消
podInfo := sched.NextPod()
}
这里的 sched.NextPod() 在上面”创建 scheduler 对象”的时候已经赋值过,它对应
// MakeNextPodFunc returns a function to retrieve the next pod from a given
// scheduling queue
func MakeNextPodFunc(queue SchedulingQueue) func() *framework.QueuedPodInfo {
return func() *framework.QueuedPodInfo {
podInfo, err := queue.Pop()
if err == nil {
klog.V(4).InfoS("About to try and schedule pod", "pod", klog.KObj(podInfo.Pod))
for plugin := range podInfo.UnschedulablePlugins {
metrics.UnschedulableReason(plugin, podInfo.Pod.Spec.SchedulerName).Dec()
}
return podInfo
}
klog.ErrorS(err, "Error while retrieving next pod from scheduling queue")
return nil
}
}
这里调用 优先队列的 PriorityQueue.Pop() 方法获取一个 Pod 信息。
// Pop removes the head of the active queue and returns it. It blocks if the
// activeQ is empty and waits until a new item is added to the queue. It
// increments scheduling cycle when a pod is popped.
func (p *PriorityQueue) Pop() (*framework.QueuedPodInfo, error) {
p.lock.Lock()
defer p.lock.Unlock()
// 阻塞
for p.activeQ.Len() == 0 {
// When the queue is empty, invocation of Pop() is blocked until new item is enqueued.
// When Close() is called, the p.closed is set and the condition is broadcast,
// which causes this loop to continue and return from the Pop().
if p.closed {
return nil, fmt.Errorf(queueClosed)
}
p.cond.Wait()
}
// 弹出Pod
obj, err := p.activeQ.Pop()
if err != nil {
return nil, err
}
// 递增
pInfo := obj.(*framework.QueuedPodInfo)
pInfo.Attempts++
p.schedulingCycle++
return pInfo, nil
}
从注释里我们可知,它是以block的方式从 actieQ 队列获取一个 Pod,如果队列为空,则将一直等待,至到一个新的Pod被添加到队列。同时当Pod被 Pop() 走后,scheduling cycle 的值将递增。
获取调度 Framework
根据当前Pod调度器 pod.schedulerName 获取其对应的 Framework
func (sched *Scheduler) scheduleOne(ctx context.Context) {
// 2. 根据当前Pod调度器 pod.schedulerName 获取其对应的 Framework
fwk, err := sched.frameworkForPod(pod)
// 检查是否需要跳过调度
if sched.skipPodSchedule(fwk, pod) {
return
}
}
调用 sched.skipPodSchedule(fwk, pod) 函数来检查是否需要跳过调度操作。如果这个Pod正处于删除状态(pod.DeletionTimestamp != nil)或者明确指定了不需要调度,则直接结束本次调度;
节点选择
节点选择有以下步骤:
- 找一个节点
- 修改
pod.Spec.NodeName = NodeName属性,建立Pod与Node映射关系 - 执行一系列插件
- 根据需要将一些Pod移到 activeQ 队列
下面我们先看一下找节点这一步
找节点
为了能将执行Pod,必须找一个合适的Node,这一步也是 k8s 中必须关注的一块内容
// 3. 获取一个最合适的节点
scheduleResult, assumedPodInfo, status := sched.schedulingCycle(schedulingCycleCtx, state, fwk, podInfo, start, podsToActivate)
可以看到,对于节点的选择是在 sched.schedulingCycle()函数里又调用了一个 sched.SchedulePod 函数来实现的。
// schedulingCycle tries to schedule a single Pod.
func (sched *Scheduler) schedulingCycle(
ctx context.Context,
state *framework.CycleState,
fwk framework.Framework,
podInfo *framework.QueuedPodInfo,
start time.Time,
podsToActivate *framework.PodsToActivate,
) (ScheduleResult, *framework.QueuedPodInfo, *framework.Status) {
pod := podInfo.Pod
// 一、 获取一个合适的节点,这块下面有详细介绍
scheduleResult, err := sched.SchedulePod(ctx, fwk, state, pod)
if err != nil {
...
return err
}
这里根据 sched.SchedulePod() 源码实现,共有以下步骤:
- 更新节点快照
sched.nodeInfoSnapshot - 检查节点快照
sched.nodeInfoSnapshot里节点数量,如果为 `` ,则直接结束 - 基于 Framework 过滤插件和过滤扩展查找适合Pod的节点(plugins 和 extenders 发挥使用)
- 如果只有一个节点的话,直接返回使用这个节点并结束
- 如果存在多个节点的话,则调用
prioritizeNodes函数,通过运行fwk.RunScorePlugins()函数对每个节点进行打分,并对每个节点记录每个插件的打分和统计节点总得分 - 调用
selectHost()遍历一次所有节点,找出来得分最高的节点
下面我们看一下源码实现,并在重要的地方做了一些注释。
如果获取节点成功,则返回 ScheduleResult,否则返回一个 FitError数据结构。
更新节点快照
// schedulePod tries to schedule the given pod to one of the nodes in the node list.
func (sched *Scheduler) schedulePod(ctx context.Context, fwk framework.Framework, state *framework.CycleState, pod *v1.Pod) (result ScheduleResult, err error) {
// 1. 更新节点快照,为什么更新?为什么用?每调度一个Pod就会更新Node快照,性能是否存在问题
if err := sched.Cache.UpdateSnapshot(sched.nodeInfoSnapshot); err != nil {
return result, err
}
}
检查快照节点数量
// schedulePod tries to schedule the given pod to one of the nodes in the node list.
func (sched *Scheduler) schedulePod(ctx context.Context, fwk framework.Framework, state *framework.CycleState, pod *v1.Pod) (result ScheduleResult, err error) {
// 2. 检查节点快照有无节点
if sched.nodeInfoSnapshot.NumNodes() == 0 {
return result, ErrNoNodesAvailable
}
}
找出所有可使用的Node清单
然后为 Pod 寻找所有适合此Pod 运行的 node 清单
// 3. 查找合适的节点
feasibleNodes, diagnosis, err := sched.findNodesThatFitPod(ctx, fwk, state, pod)
只有一个节点直接使用
如果当前只有一个节点的话,则此时不用考虑其它情况,直接使用此节点并返回。
// 4. 正好只有一个节点,直接使用
// When only one node after predicate, just use it.
if len(feasibleNodes) == 1 {
return ScheduleResult{
SuggestedHost: feasibleNodes[0].Name,
EvaluatedNodes: 1 + len(diagnosis.NodeToStatusMap),
FeasibleNodes: 1,
}, nil
}
多节点则进行打分
如果有多个节点的话,则在这些节点上调用函数 RunScorePlugins() 再执行插件评分。
// 5. 从多个节点中选择最合适的节点
priorityList, err := prioritizeNodes(ctx, sched.Extenders, fwk, state, pod, feasibleNodes)
每个插件都会对当前节点进行计算,得出当前节点评分,同时还要将所有插件的评分累计,作为节点的总评分。
找出评分最高的节点
// 6. 从丛多节点中遍历出来评分最高的那个,每个节点都会调用所有plugins对其进行评分
host, err := selectHost(priorityList)
然后遍历所有节点,筛选出来得分最高的节点,这里的 host 变量即是节点的名称。
最后将获取节点返回
return ScheduleResult{
SuggestedHost: host, // 选择的节点名称(这里是指主机名还是系统内部分配的一个标识?)
EvaluatedNodes: len(feasibleNodes) + len(diagnosis.NodeToStatusMap),
FeasibleNodes: len(feasibleNodes),
}, err
这里 ScheduleResult 结构体为
// ScheduleResult represents the result of scheduling a pod.
type ScheduleResult struct {
// 节点名称
SuggestedHost string
//调度程序在筛选阶段及以后评估pod的节点数
EvaluatedNodes int
// 评估后,适合pod的节点数量
FeasibleNodes int
// 调度周期相关
nominatingInfo *framework.NominatingInfo
}
至此,节点找好了,不过还有一些工作要做。
修改Pod的属性
通过修改 Pod.Spec.NodeName=NodeName 属性,建立Pod与Node之间的映射关系。告诉 cache 这个pod已与上面选择的node建立了绑定关系(其实还没有真正绑定),只是在cache里对其建立了绑定关系。
接着再从队列里将这个Pod删除。
func (sched *Scheduler) schedulingCycle(...) {
assumedPodInfo := podInfo.DeepCopy()
assumedPod := assumedPodInfo.Pod
// 二、修改 Pod.Spec.NodeName = NodeName,建立 Pod 与 Node 的映射关系
err = sched.assume(assumedPod, scheduleResult.SuggestedHost)
...
}
func (sched *Scheduler) assume(assumed *v1.Pod, host string) error {
// pod 所在Node
assumed.Spec.NodeName = host
// 缓存更新
if err := sched.Cache.AssumePod(assumed); err != nil {
klog.ErrorS(err, "Scheduler cache AssumePod failed")
return err
}
// 从内部缓存中删除
if sched.SchedulingQueue != nil {
sched.SchedulingQueue.DeleteNominatedPodIfExists(assumed)
}
return nil
}
执行插件
执行 reserve 插件的 Reserve() 方法 和 执行 Permit 插件。
func (sched *Scheduler) schedulingCycle(...) {
// 三、执行一些插件
// Run the Reserve method of reserve plugins.
if sts := fwk.RunReservePluginsReserve(ctx, state, assumedPod, scheduleResult.SuggestedHost); !sts.IsSuccess() {}
// Run "permit" plugins.
runPermitStatus := fwk.RunPermitPlugins(ctx, state, assumedPod, scheduleResult.SuggestedHost)
if !runPermitStatus.IsWait() && !runPermitStatus.IsSuccess() {
}
}
将 Pod 转到 activeQ 队列
如果 podsToActive.Map 存在Pod,则将它们从 backoffQ 或unschedulablePods 中移到 activeQ
func (sched *Scheduler) schedulingCycle(...) {
// 四、podsToActivate.Map值被插件修改,什么情况下会插件会修改?
// At the end of a successful scheduling cycle, pop and move up Pods if needed.
if len(podsToActivate.Map) != 0 {
// 将pod 从 backoffQ 或unschedulablePods 中移到 activeQ
sched.SchedulingQueue.Activate(podsToActivate.Map)
// Clear the entries after activation.
podsToActivate.Map = make(map[string]*v1.Pod)
}
return scheduleResult, assumedPodInfo, nil
}
疑问:
podsToActivate.Map 什么时候可能被修改?
异步绑定Pod与Node
// 异步绑定 Pod 与 node
go func() {
bindingCycleCtx, cancel := context.WithCancel(ctx)
defer cancel()
// 绑定
status := sched.bindingCycle(bindingCycleCtx, state, fwk, scheduleResult, assumedPodInfo, start, podsToActivate)
if !status.IsSuccess() {
sched.handleBindingCycleError(bindingCycleCtx, state, fwk, assumedPodInfo, start, scheduleResult, status)
}
}()
可以看到对于pod与节点 node的绑定是异步的,其由绑定函数 bindingCycle() 实现
func (sched *Scheduler) bindingCycle( ctx context.Context,
state *framework.CycleState,
fwk framework.Framework,
scheduleResult ScheduleResult,
assumedPodInfo *framework.QueuedPodInfo,
start time.Time,
podsToActivate *framework.PodsToActivate) *framework.Status {
assumedPod := assumedPodInfo.Pod
// 执行 "permit" 插件.
if status := fwk.WaitOnPermit(ctx, assumedPod); !status.IsSuccess() {
return status
}
// Run "prebind" plugins.
if status := fwk.RunPreBindPlugins(ctx, state, assumedPod, scheduleResult.SuggestedHost); !status.IsSuccess() {
return status
}
// Run "bind" plugins. 真正绑定的地方
if status := sched.bind(ctx, fwk, assumedPod, scheduleResult.SuggestedHost, state); !status.IsSuccess() {
return status
}
// Run "postbind" plugins.
fwk.RunPostBindPlugins(ctx, state, assumedPod, scheduleResult.SuggestedHost)
// At the end of a successful binding cycle, move up Pods if needed.
if len(podsToActivate.Map) != 0 {
sched.SchedulingQueue.Activate(podsToActivate.Map)
// Unlike the logic in schedulingCycle(), we don't bother deleting the entries
// as `podsToActivate.Map` is no longer consumed.
}
return nil
}
可能看到在异步绑定 Pod与Node 时,将会依次执行下面的插件
- permit
- prebind
- bind
- postbind
在最后,如果 podsToActive.Map 不为空的话,则需要将这些 Pod 移到 activeQ 队列里,但这里并不将这些Pod信息从podsToActivate.Map 中删除,这个与上面 schedulingCycle() 有些不一样。
其中 sched.bind 绑定操作在 RunBindPlugins() 执行的
// RunBindPlugins runs the set of configured bind plugins until one returns a non `Skip` status.
func (f *frameworkImpl) RunBindPlugins(ctx context.Context, state *framework.CycleState, pod *v1.Pod, nodeName string) (status *framework.Status) {
startTime := time.Now()
defer func() {
metrics.FrameworkExtensionPointDuration.WithLabelValues(metrics.Bind, status.Code().String(), f.profileName).Observe(metrics.SinceInSeconds(startTime))
}()
// bind插件不存在
if len(f.bindPlugins) == 0 {
return framework.NewStatus(framework.Skip, "")
}
logger := klog.FromContext(ctx)
logger = klog.LoggerWithName(logger, "Bind")
// TODO(knelasevero): Remove duplicated keys from log entry calls
// When contextualized logging hits GA
// https://github.com/kubernetes/kubernetes/issues/111672
logger = klog.LoggerWithValues(logger, "pod", klog.KObj(pod), "node", klog.ObjectRef{Name: nodeName})
// 执行注册的所有 bind 插件
for _, pl := range f.bindPlugins {
logger := klog.LoggerWithName(logger, pl.Name())
ctx := klog.NewContext(ctx, logger)
// 执行绑定插件
status = f.runBindPlugin(ctx, pl, state, pod, nodeName)
if status.IsSkip() {
continue
}
if !status.IsSuccess() {
if status.IsUnschedulable() {
logger.V(4).Info("Pod rejected by Bind plugin", "pod", klog.KObj(pod), "node", nodeName, "plugin", pl.Name(), "status", status.Message())
status.SetFailedPlugin(pl.Name())
return status
}
err := status.AsError()
logger.Error(err, "Plugin Failed", "plugin", pl.Name(), "pod", klog.KObj(pod), "node", nodeName)
return framework.AsStatus(fmt.Errorf("running Bind plugin %q: %w", pl.Name(), err))
}
return status
}
return status
}
// 执行绑定插件
func (f *frameworkImpl) runBindPlugin(ctx context.Context, bp framework.BindPlugin, state *framework.CycleState, pod *v1.Pod, nodeName string) *framework.Status {
if !state.ShouldRecordPluginMetrics() {
// 执行插件的 Bind() 方法
return bp.Bind(ctx, state, pod, nodeName)
}
startTime := time.Now()
// 执行插件的 Bind() 方法
status := bp.Bind(ctx, state, pod, nodeName)
f.metricsRecorder.ObservePluginDurationAsync(metrics.Bind, bp.Name(), status.Code().String(), metrics.SinceInSeconds(startTime))
return status
}
至此,Pod 与 Node 绑定关系正式完成。
总结
可以看到插件在整个调度过程中极其的重要,这里并没有对其进行详细介绍。大家可以了解一下每个内置插件的作用,同时还有扩展器的作用。
参考资源
- The Kubernetes Scheduler
- Scheduler Algorithm in Kubernetes
- https://github.com/kubernetes/community/blob/master/contributors/devel/sig-scheduling/scheduler_queues.md
- https://github.com/kubernetes/community/blob/master/contributors/devel/sig-scheduling/scheduler_framework_plugins.md
- https://kubernetes.io/zh-cn/docs/concepts/scheduling-eviction/scheduling-framework/
- https://github.com/kubernetes-sigs/scheduler-plugins
- https://kubernetes.io/zh-cn/docs/reference/scheduling/config/
- https://github.com/kubernetes-sigs/scheduler-plugins/blob/master/doc/develop.md
- https://mp.weixin.qq.com/s/FGzwDsrjCNesiNbYc3kLcA