创建Pod源码解析
admin
- 18 minutes read - 3785 words在上一篇《Kubelet 服务引导流程》中我们介绍了 kubelet 服务启动的大致流程,其中提到过对 Pod 的管理,这一节将详细介绍一下对Pod的相关操作,如创建、修改、删除等操作。建议先了解一下上节介绍的内容。
在 kubelet 启动的时候,会通过三种 pod source 方式来获取 pod 信息:
- file: 这种方式只要针对 staticPod 来处理,定时观察配置文件是否发生变更情况来写入 pod
- http方式: 就是通过一个http请求一个 URL 地址,用来获取
simple Pod信息 - clientSet: 这种方式直接与 APIServer 通讯,对 pod 进行watch
上面这三种 pod source ,一旦有pod 的变更信息,将直接写入一个 kubetypes.PodUpdate 这个 channel(参考: https://github.com/kubernetes/kubernetes/blob/v1.27.3/pkg/kubelet/kubelet.go#L278-L313),然后由下面我们要讲的内容进行读取消费。
对于pod 的操作除了这一个地方可以实现对 pod 的操作,还有l四个地方也可以触发对 pod 的操作。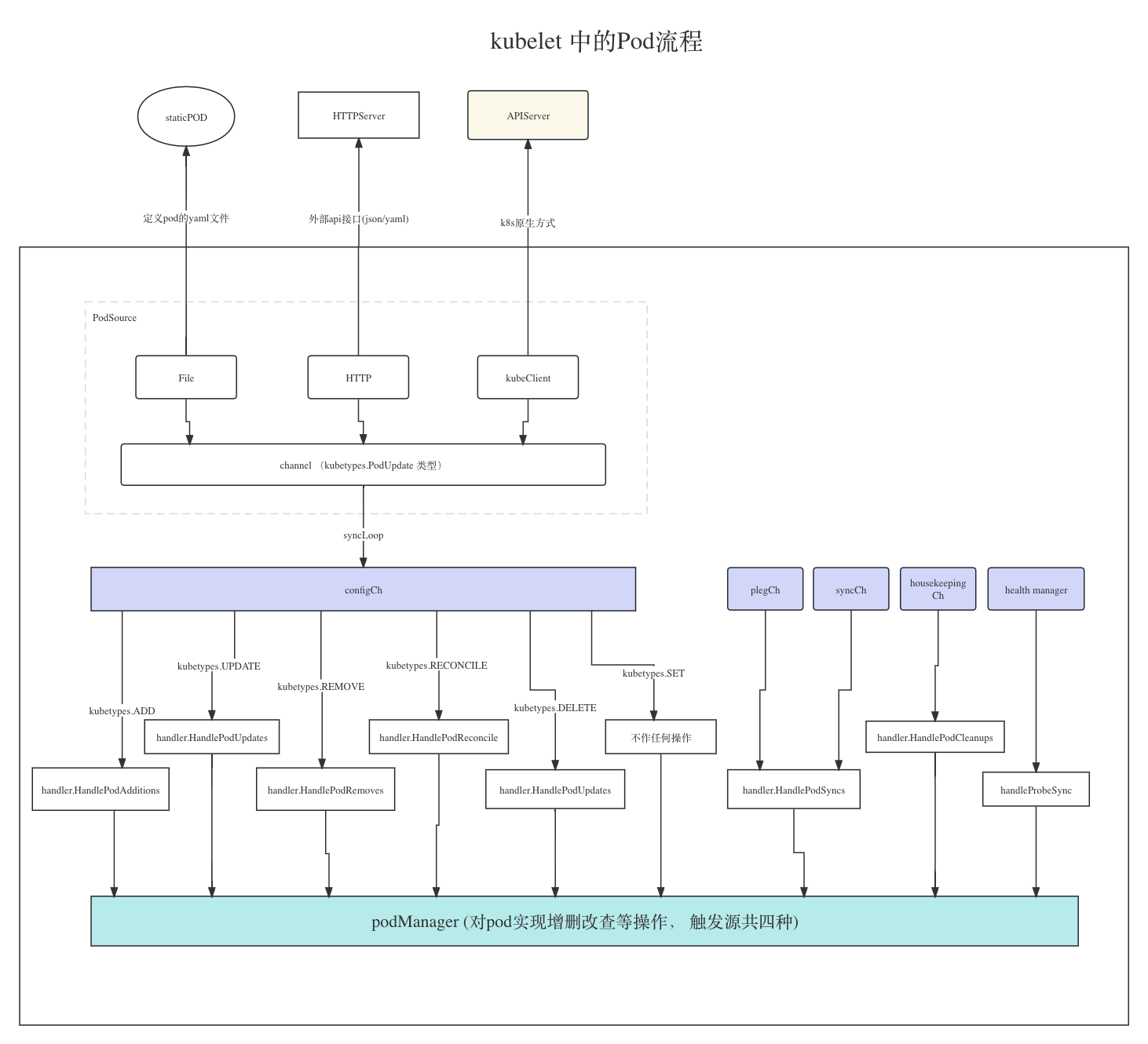
在启动服务函数 Kubelet.Run(updates <-chan kubetypes.PodUpdate{}) 中参数 updates是一个 kubetypes.PodUpdate的类型,其结构如下
type PodUpdate struct {
Pods []*v1.Pod
Op PodOperation
Source string
}
// PodOperation 定义了将对pod配置进行哪些更改。
type PodOperation int
// These constants identify the PodOperations that can be made on a pod configuration.
const (
// SET is the current pod configuration.
SET PodOperation = iota
// ADD signifies pods that are new to this source.
ADD
// DELETE signifies pods that are gracefully deleted from this source.
DELETE
// REMOVE signifies pods that have been removed from this source.
REMOVE
// UPDATE signifies pods have been updated in this source.
UPDATE
// RECONCILE signifies pods that have unexpected status in this source,
// kubelet should reconcile status with this source.
RECONCILE
)
PodUpdate 定义了一个操作 pod 对象,你可以发送一个 Op == ADD|REMOVE 的Pod切片对象(当REMOVE时,只需要ID); 如果设置 Op == SET将表示Pod 当前的配置状态(表示未发生任何变化);如果要移除所有pod,请将pods设置为空对象,将Op设置为SET。
此外,对于 PodUpdate.Pods 永远也不能为 nil,它应该是一个指向空切片的指针(言外之意就是说支持Pod批量操作)。
在函数的最后一步调用了 kl.syncLoop(ctx, updates, kl) 这个函数,我们可以视其为入口函数。
func (kl *Kubelet) Run(updates <-chan kubetypes.PodUpdate) {
...
// Start the pod lifecycle event generator.
kl.pleg.Start()
if utilfeature.DefaultFeatureGate.Enabled(features.EventedPLEG) {
kl.eventedPleg.Start()
}
kl.syncLoop(ctx, updates, kl)
}
第一个参数 updates 是一个 kubetypes.PodUpdate 类型,上面已经介绍过,第二个参数 kl 实现的是一个接口,这里它就是 kubelet 对象本身。
// SyncHandler is an interface implemented by Kubelet, for testability
type SyncHandler interface {
HandlePodAdditions(pods []*v1.Pod)
HandlePodUpdates(pods []*v1.Pod)
HandlePodRemoves(pods []*v1.Pod)
HandlePodReconcile(pods []*v1.Pod)
HandlePodSyncs(pods []*v1.Pod)
HandlePodCleanups(ctx context.Context) error
}
从方法全名基本就看出来它是用来处理Pod变更的,我们看一下 [syncLoop](https://github.com/kubernetes/kubernetes/blob/v1.27.3/pkg/kubelet/kubelet.go#L2251-L2296) 函数实现。
https://github.com/kubernetes/kubernetes/blob/v1.27.3/pkg/kubelet/kubelet.go#L2251-L2296
func (kl *Kubelet) syncLoop(ctx context.Context, updates <-chan kubetypes.PodUpdate, handler SyncHandler) {
...
for {
...
kl.syncLoopMonitor.Store(kl.clock.Now())
// 重点
if !kl.syncLoopIteration(ctx, updates, handler, syncTicker.C, housekeepingTicker.C, plegCh) {
break
}
kl.syncLoopMonitor.Store(kl.clock.Now())
}
}
syncLoop 是一个主循环,可以监听 channel (file, apiserver, 和 http 三种 pod source 的pod变更并合并它们)。对于发生任何变更则对比他们的 desired state 和当前的 running state。如果未监听到任何变化,也会定期的执行状态对比。
接着我们看一下[syncLoopIteration(ctx, updates, handler, syncTicker.C, housekeepingTicker.C, plegCh)](https://github.com/kubernetes/kubernetes/blob/v1.27.3/pkg/kubelet/kubelet.go#L2298-L2437) 函数。参数介绍
configCh: 从中读取配置事件的通道,也就是形参updateshandler: 将 pod 分发到的SyncHandlersyncCh: 读取周期性同步事件的通道,当前固定为1秒housekeepingCh: 读取 housekeeping 事件的通道plegCh: 读取 PLEG 更新的通道
这里我们只分析 configCh 这种 config source 情况。
Pod 操作
当 configCh 有消息时,将根据pod操作类型触发相应的函数
func (kl *Kubelet) syncLoopIteration(ctx context.Context, configCh <-chan kubetypes.PodUpdate, handler SyncHandler,
syncCh <-chan time.Time, housekeepingCh <-chan time.Time, plegCh <-chan *pleg.PodLifecycleEvent) bool {
select {
case u, open := <-configCh:
// 变更回调
if !open {
klog.ErrorS(nil, "Update channel is closed, exiting the sync loop")
return false
}
switch u.Op {
case kubetypes.ADD:
// After restarting, kubelet will get all existing pods through
// ADD as if they are new pods. These pods will then go through the
// admission process and *may* be rejected. This can be resolved
// once we have checkpointing.
handler.HandlePodAdditions(u.Pods)
case kubetypes.UPDATE:
handler.HandlePodUpdates(u.Pods)
case kubetypes.REMOVE:
handler.HandlePodRemoves(u.Pods)
case kubetypes.RECONCILE:
handler.HandlePodReconcile(u.Pods)
case kubetypes.DELETE:
handler.HandlePodUpdates(u.Pods)
case kubetypes.SET:
klog.ErrorS(nil, "Kubelet does not support snapshot update")
default:
klog.ErrorS(nil, "Invalid operation type received", "operation", u.Op)
}
// 添加配置源
kl.sourcesReady.AddSource(u.Source)
case e := <-plegCh:
...
case <-syncCh:
...
case update := <-kl.readinessManager.Updates():
...
case update := <-kl.startupManager.Updates():
...
case <-housekeepingCh:
...
}
return true
}
事件类型及调用回调函数对应关系
kubetypes.ADD 调用 handler.HandlePodAdditions(u.Pods)
kubetypes.UPDATE: 调用 handler.HandlePodUpdates(u.Pods)
kubetypes.REMOVE: 调用 handler.HandlePodRemoves(u.Pods)
kubetypes.RECONCILE: 调用 handler.HandlePodReconcile(u.Pods)
kubetypes.DELETE: 调用 handler.HandlePodUpdates(u.Pods), 同 kubetypes.UPDATE 一样
kubetypes.SET: 暂时不做任何操作
Add 添加Pod
func (kl *Kubelet) HandlePodAdditions(pods []*v1.Pod) {
// 1. 根据创建时间升序排序
sort.Sort(sliceutils.PodsByCreationTime(pods))
for _, pod := range pods {
// 返回 regularPod及其规范
existingPods := kl.podManager.GetPods()
// 2. 添加Pod到podManager
kl.podManager.AddPod(pod)
// 3. 如果是 mirrorPod, 则直接 handleMirrorPod() 并返回
if kubetypes.IsMirrorPod(pod) {
kl.handleMirrorPod(pod, start)
continue
}
// 4. 当前Pod已被发送 Termination 请求
if !kl.podWorkers.IsPodTerminationRequested(pod.UID) {
// We failed pods that we rejected, so activePods include all admitted
// pods that are alive.
// 排除 已终止/发送终止请求/处于终止阶段 类的Pods
activePods := kl.filterOutInactivePods(existingPods)
// 启用 InPlacePodVerticalScaling 特性
if utilfeature.DefaultFeatureGate.Enabled(features.InPlacePodVerticalScaling) {
// 调整cpu 和 内存
podCopy := pod.DeepCopy()
for _, c := range podCopy.Spec.Containers {
allocatedResources, found := kl.statusManager.GetContainerResourceAllocation(string(pod.UID), c.Name)
if c.Resources.Requests != nil && found {
c.Resources.Requests[v1.ResourceCPU] = allocatedResources[v1.ResourceCPU]
c.Resources.Requests[v1.ResourceMemory] = allocatedResources[v1.ResourceMemory]
}
}
// 检查当前pod是否允许准入
if ok, reason, message := kl.canAdmitPod(activePods, podCopy); !ok {
kl.rejectPod(pod, reason, message)
continue
}
// For new pod, checkpoint the resource values at which the Pod has been admitted
if err := kl.statusManager.SetPodAllocation(podCopy); err != nil {
klog.ErrorS(err, "SetPodAllocation failed", "pod", klog.KObj(pod))
}
} else {
// 检查当前pod是否允许准入
if ok, reason, message := kl.canAdmitPod(activePods, pod); !ok {
kl.rejectPod(pod, reason, message)
continue
}
}
}
// 5. 获取对应的mirrorPod,在 pod worker 中异步同步pod
mirrorPod, _ := kl.podManager.GetMirrorPodByPod(pod)
kl.dispatchWork(pod, kubetypes.SyncPodCreate, mirrorPod, start)
}
}
这里kl.podManager是一个门面,可以将其理解为 kubelet 的一个组件,它抽象了Kubelet服务的pods的各种来源( 后面会介绍)。
Pod InPlacePodVerticalScaling是Kubernetes中的一个功能,用于在保持Pod运行的同时,对Pod的资源配置进行垂直扩缩容。它允许你调整Pod的CPU和内存资源配置,而无需删除或重新创建Pod。
InPlacePodVerticalScaling的主要优势在于可以避免中断应用程序的操作,例如在水平扩展时,需要先删除旧的Pod,然后创建新的Pod。相比之下,垂直扩容不影响正在运行的Pod,并且会动态地增加或减少Pod的资源配置。
使用InPlacePodVerticalScaling时,你可以通过更新Pod配置的CPU和内存资源限制来实现垂直扩缩容。Kubernetes将根据新的资源配置来重新分配资源,并在不中断应用程序的情况下继续运行Pod。
需要注意的是,InPlacePodVerticalScaling适用于对资源的简单垂直扩缩容,如果需要更复杂的调整和操作,可能需要考虑使用其他更为灵活的扩展方法。
对于上面的每一个步骤已进行了注释,可以看到对pod 的操作,是需要先根据普通pod对应的 mirror pod ,然后调用 kl.dispatchWork()函数实现在一个 pod worker 中进行异步同步。
步骤
- podManager 中 Add 新 Pod
- 调用 dispatchWork() 异步同步
这里同步类型为 kubetypes.SyncPodCreate,同步类型 SyncPodType 一共有四类:
SyncPodSync 表示pod已同步为 desired state
SyncPodUpdate 表示 Pod 从 source 更新
SyncPodCreate 表示 Pod 从 source 创建
SyncPodKill 表示当前Pod中没有处于运行中的 containers,对于已 stopped 的Pod 未来可能被重启。
Update 更新Pod
func (kl *Kubelet) HandlePodUpdates(pods []*v1.Pod) {
start := kl.clock.Now()
for _, pod := range pods {
// 1. UpdatePod
kl.podManager.UpdatePod(pod)
// 2. dispatchWork
if kubetypes.IsMirrorPod(pod) {
kl.handleMirrorPod(pod, start)
continue
}
mirrorPod, _ := kl.podManager.GetMirrorPodByPod(pod)
kl.dispatchWork(pod, kubetypes.SyncPodUpdate, mirrorPod, start)
}
}
步骤
- podManager 中更新 Pod
- 调用 dispatchWork() 异步同步
同步类型为 kubetypes.SyncPodUpdate
REMOVE 移除Pod
func (kl *Kubelet) HandlePodRemoves(pods []*v1.Pod) {
start := kl.clock.Now()
for _, pod := range pods {
// DeletePod
kl.podManager.DeletePod(pod)
// 如果是mirrorPod, 则读取出来其对应的 staticPod, 然后再直接 kl.dispatchWork
if kubetypes.IsMirrorPod(pod) {
kl.handleMirrorPod(pod, start)
continue
}
// Deletion is allowed to fail because the periodic cleanup routine
// will trigger deletion again.
if err := kl.deletePod(pod); err != nil {
klog.V(2).InfoS("Failed to delete pod", "pod", klog.KObj(pod), "err", err)
}
}
}
对于mirrorPod 和 staticPod 的下面会介绍到。
DELETE 删除Pod
同 kubetypes.UPDATE 一样
RECONCILE 调和Pod
func (kl *Kubelet) HandlePodReconcile(pods []*v1.Pod) {
start := kl.clock.Now()
for _, pod := range pods {
// 1. UpdatePod
kl.podManager.UpdatePod(pod)
// 2. pod为 ready 状态,则调用 dispatchWork() 进行pod同步
// Reconcile Pod "Ready" condition if necessary. Trigger sync pod for reconciliation.
if status.NeedToReconcilePodReadiness(pod) {
mirrorPod, _ := kl.podManager.GetMirrorPodByPod(pod)
kl.dispatchWork(pod, kubetypes.SyncPodSync, mirrorPod, start)
}
// 如果pod已处于 evicted 状态,则直接删除所有相关containers
// After an evicted pod is synced, all dead containers in the pod can be removed.
if eviction.PodIsEvicted(pod.Status) {
if podStatus, err := kl.podCache.Get(pod.UID); err == nil {
kl.containerDeletor.deleteContainersInPod("", podStatus, true)
}
}
}
}
步骤
- podManager 中更新 Pod
- 调用 dispatchWork() 异步同步
同步类型为 kubetypes.SyncPodSync。
相比其它几种情况,多了一个 pod状态为 evicted 的处理情况
总结
对于几上几种类型操作,基本都会先对 podManager 进行类似的操作,然后调用 dispatchWork() 函数进行Pod同步。
那我们再看看这个函数 dispatchWork() 都干了什么。
func (kl *Kubelet) dispatchWork(pod *v1.Pod, syncType kubetypes.SyncPodType, mirrorPod *v1.Pod, start time.Time) {
// Run the sync in an async worker.
kl.podWorkers.UpdatePod(UpdatePodOptions{
Pod: pod,
MirrorPod: mirrorPod,
UpdateType: syncType,
StartTime: start,
})
...
}
这里直接调用函数 kl.podWorkers.UpdatePod() 以异步的方式对Pod进行同步,函数参数 UpdatePodOptions 是一个 UpdatePod 专用的数据类型,它的数据结构为
type UpdatePodOptions struct {
UpdateType types.SyncPodType
StartTime time.Time
Pod *v1.Pod
MirrorPod *v1.Pod
RunningPod *container.Pod
KillPodOptions *KillPodOptions
}
字段解释
UpdateType: 更新类型,值可以为 create,update,sync, kill
StartTime: 可选字段。创建此更新时的时间戳
Pod: 要更新的Pod
MirrorPod: 如果pod是静态pod,那么MirrorPod就是镜像pod。如果 UpdateType为kill 或 terminated 时为可选。
RunningPod: RunningPod是一个 runtime pod,表示它在配置中已不存在。如果Pod为 nil 则为必需的,如果设置了Pod,则可以忽略
KillPodOptions: KillPodOptions用于覆盖pod的默认终止行为,或在操作完成后更新pod状态。由于pod可能因多种原因而被终止,因此 PodStatusFunc 会按顺序调用,以后的终止有机会覆盖状态(抢占稍后可能会变成驱逐)。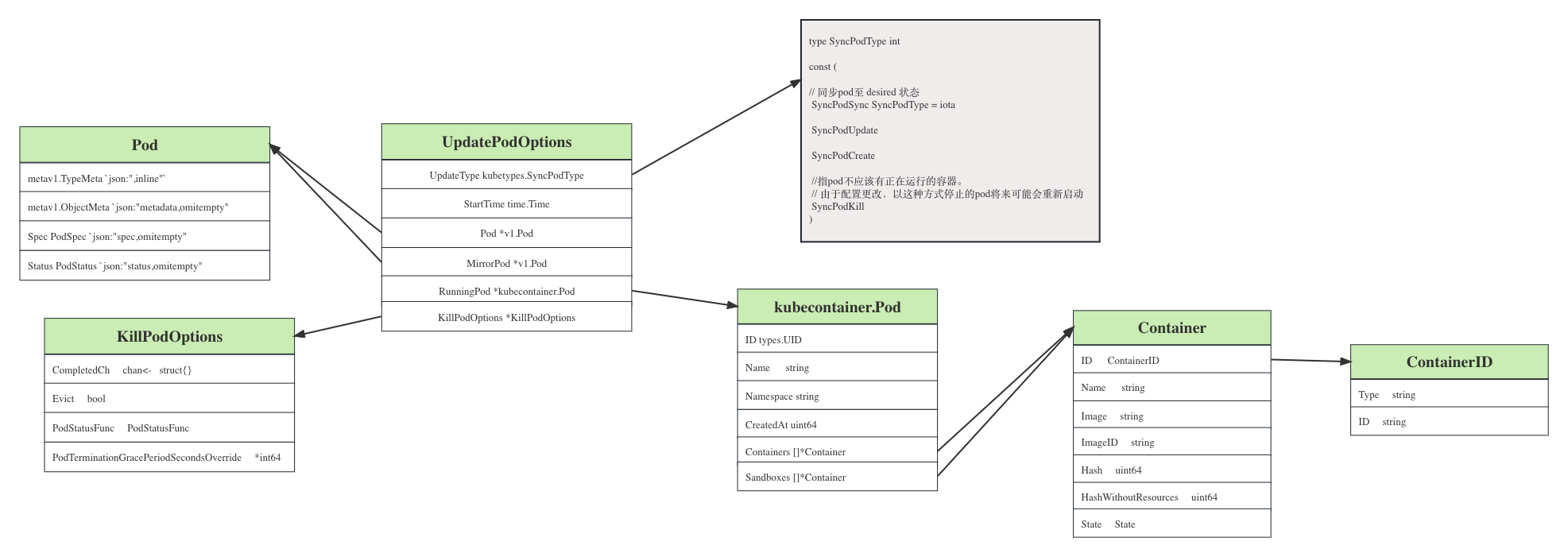
从结构关系图中可以看到,有两种不同的 Pod 数据类型,一种是通用的 Pod 元数据,另一种是只对Pod里的container相关信息,在 UpdatePodOptions.Pod 为 nil 的时候,UpdatePodOptions.RunningPod 字段值是必须的。
podWorker 组件
这里 podWorker 是 kubelet 中的一个组件,主要实现对Pod 进行一系列的操作,它必须实现一个 PodWorkers 接口,接口定义如下
type PodWorkers interface {
UpdatePod(options UpdatePodOptions)
SyncKnownPods(desiredPods []*v1.Pod) (knownPods map[types.UID]PodWorkerSync)
IsPodKnownTerminated(uid types.UID) bool
CouldHaveRunningContainers(uid types.UID) bool
ShouldPodBeFinished(uid types.UID) bool
IsPodTerminationRequested(uid types.UID) bool
ShouldPodContainersBeTerminating(uid types.UID) bool
ShouldPodRuntimeBeRemoved(uid types.UID) bool
ShouldPodContentBeRemoved(uid types.UID) bool
IsPodForMirrorPodTerminatingByFullName(podFullname string) bool
}
UpdatePod()
通知 pod worker对一个pod做出变更,然后由每一个goroutine 按 FIFO 的顺序进行处理(UID)。
pod 的状态将被传递给 syncPod 方法,直到pod 被标记为已 deleted,它到达 terminal阶段(成功/失败)或者pod被kubelet驱逐。一旦发生这种情况,syncTerminatingPod 方法将被调用直到它成功退出,之后所有的 UpdatePod() 调用也将被忽略,直到过期。
一个Pod 如果是 terminated 状态,则永远也不可能被重启。
SyncKnownPods()
删除那些不在 desiredPods 集合中并且已终止相当长一段时间的pods的 workers。一旦该方法被调用一次wokers 就被认为是完全初始化的,随后对未知pod上 ShouldPodContentBeRemoved 的调用将返回 true。它返回一个map 类型,描述每个已知 pod workers 的状态。调用方有责任重新添加任何未作为knownPods返回的所需pod。
IsPodKnownTerminated()
如果 SyncTerminatingPod() 成功完成,则返回 true。通过提供 pod UID pod worker 就可以终止。如果pod已被强制删除,并且pod workers 已完成终止,则此方法将返回 false,因此此方法应仅用于从所需集合中筛选出pod,例如在准入模块中。
CouldHaveRunningContainers()
一旦pod workers看到pod(可以调用syncPod),则在pod workers同步之前返回true,在pod终止之后返回false(保证停止运行容器)。
适用于kubelet配置循环,但不适用于应使用 ShouldPod*()的子系统。
其它几个接口方法这里不再介绍,可以通过其注释信息进一步了解每个方法的使用使用和使用场景。
通过分析得知函数调用链:
kl.dispatchWork() -> kl.podWorkers.UpdatePod() -> kl.podWorkers.podWorkerLoop() -> kl.podWorkers.startPodSync() -> kl.podSyncer.SyncPod() -> kl.podWorkers.completeWork()
这里 UpdatePod() 逻辑为
func (p *podWorkers) UpdatePod(options UpdatePodOptions) {
// 1. 获取Pod信息(Pod或runningPod),如uid、ns 或 name
if runningPod := options.RunningPod; runningPod != nil {
if options.Pod == nil {
uid, ns, name = runningPod.ID, runningPod.Namespace, runningPod.Name
isRuntimePod = true
} else {
options.RunningPod = nil
uid, ns, name = options.Pod.UID, options.Pod.Namespace, options.Pod.Name
}
} else {
uid, ns, name = options.Pod.UID, options.Pod.Namespace, options.Pod.Name
}
// 2. 根据 pod.UID 获取当前Pod的同步状态,如果为首次同步则设置并记录当前pod的同步状态
var firstTime bool
now := p.clock.Now()
status, ok := p.podSyncStatuses[uid]
if !ok {
// 当前Pod为首次同步
firstTime = true
status = &podSyncStatus{
syncedAt: now,
fullname: kubecontainer.BuildPodFullName(name, ns),
}
if options.Pod != nil && (options.Pod.Status.Phase == v1.PodFailed || options.Pod.Status.Phase == v1.PodSucceeded) {
if statusCache, err := p.podCache.Get(uid); err == nil {
if isPodStatusCacheTerminal(statusCache) {
status = &podSyncStatus{
terminatedAt: now,
terminatingAt: now,
syncedAt: now,
startedTerminating: true,
finished: false,
fullname: kubecontainer.BuildPodFullName(name, ns),
}
}
}
}
p.podSyncStatuses[uid] = status
}
// 3. RunningPods表示未知的pod执行,并且不包含足以执行除终止之外的任何操作的pod规范信息。这里根据不同情况给 Pod 字段赋值
pod := options.Pod
if isRuntimePod {
...
}
if status.IsFinished() {
return
}
// 非 terminate 请求处理
// check for a transition to terminating
var becameTerminating bool
if !status.IsTerminationRequested() {
}
// 4. 创建并启动一个 pod worker 的goroutine
// start the pod worker goroutine if it doesn't exist
podUpdates, exists := p.podUpdates[uid]
if !exists {
// 为当前Pod 创建一个 PodWorker专用 podUpdates 的channel, 以便于接受后期的变更信号
podUpdates = make(chan struct{}, 1)
p.podUpdates[uid] = podUpdates
// spawn a pod worker
go func() {
// 启用一个 podWorkerLoop 服务
p.podWorkerLoop(uid, outCh)
}()
}
// 5. 发送一个信号到 podUpdates channel, 通知 pod worker 这是一个 pending update
status.pendingUpdate = &options
status.working = true
select {
case podUpdates <- struct{}{}:
default:
}
if (becameTerminating || wasGracePeriodShortened) && status.cancelFn != nil {
status.cancelFn()
return
}
}
如果当前Pod为首次podUpdate,则为其开启一个podWorker goroutine,并为这个Pod创建一个podUpdates channel 以便接收 podUpdates 信号,接着便更新 status, 然后往刚才的 podUpdates channel 发送变更信号。
这里我们创建了一个podWorkerLoop 服务,在goroutine中管理pod的顺序状态更新,一旦达到最终状态就退出。
Loop 方式负责驱动Pod通过四个阶段:
- 等待启动:即保证在同一个时间内没有两个相同的ID或相同的完整名称的Pod同时运行
- 同步:通过协调所需的pod规范和pod的运行时状态来编排pod设置
- 终止:确保Pod中所有正在运行的容器都已停止
- 已终止:清理在删除pod之前必须释放的所有资源
podWorkerLoop由传递给UpdatePod的更新和SyncKnownPods()驱动。如果某个特定的同步方法失败,p.workerQueue将使用backoff进行更新,但kubelet负责触发新的UpdatePod调用。SyncKnownPods()将只重试调用方不再知道的pods。当pod转换为working->terminating或terminating->terminated时,下一次更新会立即排队,不需要kubelet操作。
func (p *podWorkers) podWorkerLoop(podUID types.UID, podUpdates <-chan struct{}) {
var lastSyncTime time.Time
for range podUpdates {
// 一、修改Pod状态为 started
ctx, update, canStart, canEverStart, ok := p.startPodSync(podUID)
if !ok {
continue
}
...
// 二、同步Pod,针对update.WorkType的三种情况:SyncPod、TerminatingPod 和 TerminatedPod
err := func() error {
// 采取适当的操作(UpdatePod阻止非法阶段)
switch {
// TerminatedPod 表示pod已停止,不能再有正在运行的容器,并且可以执行任何前台清理。
case update.WorkType == TerminatedPod:
err = p.podSyncer.SyncTerminatedPod(ctx, update.Options.Pod, status)
// TerminatingPod 是指Pod不再被设置,但某些容器可能正在运行并被销毁。
case update.WorkType == TerminatingPod:
var gracePeriod *int64
if opt := update.Options.KillPodOptions; opt != nil {
gracePeriod = opt.PodTerminationGracePeriodSecondsOverride
}
podStatusFn := p.acknowledgeTerminating(podUID)
// if we only have a running pod, terminate it directly
if update.Options.RunningPod != nil {
err = p.podSyncer.SyncTerminatingRuntimePod(ctx, update.Options.RunningPod)
} else {
err = p.podSyncer.SyncTerminatingPod(ctx, update.Options.Pod, status, gracePeriod, podStatusFn)
}
default:
// 重点:同步Pod
isTerminal, err = p.podSyncer.SyncPod(ctx, update.Options.UpdateType, update.Options.Pod, update.Options.MirrorPod, status)
}
lastSyncTime = p.clock.Now()
return err
}
// switch语句里的 err 是表示上面定义的匿名函数
var phaseTransition bool
switch {
case err == context.Canceled:
// when the context is cancelled we expect an update to already be queued
case err != nil:
// we will queue a retry
case update.WorkType == TerminatedPod:
// 1. we can shut down the worker
p.completeTerminated(podUID)
return
case update.WorkType == TerminatingPod:
// 2. completeTerminatingRuntimePod(podUID)
if update.Options.RunningPod != nil {
p.completeTerminatingRuntimePod(podUID)
return
}
// 3. otherwise we move to the terminating phase
p.completeTerminating(podUID)
phaseTransition = true
case isTerminal:
// 4 p.completeSync(podUID)
p.completeSync(podUID)
phaseTransition = true
}
// 三、重新入队 p.workQueue 队列
p.completeWork(podUID, phaseTransition, err)
}
}
整个流程可分为三个步骤:
- 试图更新 Pod 的状态为
started,调用startPodSync() - 同步Pod信息,同步操作为
SyncPod、TerminatingPod和TerminatedPod中的一个 - 将 Pod 重新加入
workQueue队列,交给下一个组件
这里通过一个for 语句遍历 podUpdates channel 实现,当收到变更信息时,才会开始执行这个流程。
更新 Pod started 状态
对于 startPodSync() 函数,会消费一个pending update,初始化上下文,决定pod是否已经started 或是否可以 started,并更新缓存过的pod状态,以便下游组件可以观察到 pod worker goroutine 正在尝试做什么。
func (p *podWorkers) startPodSync(podUID types.UID) (ctx context.Context, update podWork, canStart, canEverStart, ok bool) {
// verify we are known to the pod worker still
status, ok := p.podSyncStatuses[podUID]
if !ok {
return nil, update, false, false, false
}
// consume the pending update
update.WorkType = status.WorkType()
update.Options = *status.pendingUpdate
status.pendingUpdate = nil
select {
case <-p.podUpdates[podUID]:
// ensure the pod update channel is empty (it is only ever written to under lock)
default:
}
// initialize a context for the worker if one does not exist
if status.ctx == nil || status.ctx.Err() == context.Canceled {
status.ctx, status.cancelFn = context.WithCancel(context.Background())
}
ctx = status.ctx
// if we are already started, make our state visible to downstream components
if status.IsStarted() {
status.mergeLastUpdate(update.Options)
return ctx, update, true, true, true
}
// verify we can start
canStart, canEverStart = p.allowPodStart(update.Options.Pod)
switch {
case !canEverStart:
p.cleanupUnstartedPod(update.Options.Pod, status)
status.working = false
return ctx, update, canStart, canEverStart, true
case !canStart:
// this is the only path we don't start the pod, so we need to put the change back in pendingUpdate
status.pendingUpdate = &update.Options
status.working = false
return ctx, update, canStart, canEverStart, true
}
// 修改Pod状态为 started
status.startedAt = p.clock.Now()
status.mergeLastUpdate(update.Options)
return ctx, update, true, true, true
}
可以看到 startPodSync 函数只不过试图对 Pod 的 started 状态字段进行修改。
如果返回值参数ok为false,则表示无效的事件;如果其它参数值为false,请确保在返回之前进行适当的清理。 此方法应确保清除 status.pendingUpdate 并将其合并到 status.activeUpdate 中,或者当pod无法启动时, status.pndingUpdate 保持不变。尚未启动的pod永远不应该有activeUpdate,因为它暴露在已启动的pod上的下游组件中。
同步 Pod
首先定义一个 err 匿名函数,实现根据 update.WorkType 类型做相应的处理。对于 update.WorkType 的可选值有三种:
TerminatedPod表示pod已停止,不能再有正在运行的容器,并且可以执行任何前台清理。调用p.podSyncer.SyncTerminatedPod()函数TerminatingPod是指Pod不再被设置,但某些容器可能正在运行并被销毁。如果RunningPod == nil调用p.podSyncer.SyncTerminatingRuntimePod(),否则调用p.podSyncer.SyncTerminatingPod()SyncPod其它情况,表示 Pod 需要启动(start)并运行(running)。调用p.podSyncer.SyncPod()
这里 p.podSyncer 是一个 podWorker 组件( podWorker初始化),这里其实就是 kubelet 这个对象,而 p.podSyncer.SyncPod() 对应的正是 [kubelet.SyncPod()](https://github.com/kubernetes/kubernetes/blob/v1.27.3/pkg/kubelet/kubelet.go#L1607-L1922) 函数 ,先看一下此函数的注释信息,详细介绍了其工作流程, 下面对其注释进行一下翻译
// SyncPod is the transaction script for the sync of a single pod (setting up)
// a pod. This method is reentrant and expected to converge a pod towards the
// desired state of the spec. The reverse (teardown) is handled in
// SyncTerminatingPod and SyncTerminatedPod. If SyncPod exits without error,
// then the pod runtime state is in sync with the desired configuration state
// (pod is running). If SyncPod exits with a transient error, the next
// invocation of SyncPod is expected to make progress towards reaching the
// desired state. SyncPod exits with isTerminal when the pod was detected to
// have reached a terminal lifecycle phase due to container exits (for
// RestartNever or RestartOnFailure) and the next method invoked will be
// SyncTerminatingPod. If the pod terminates for any other reason, SyncPod
// will receive a context cancellation and should exit as soon as possible.
翻译过来大概意思:
SyncPod 是同步单个Pod的事务脚本(进行Pod设置)。该方法是可重入的,并且期望将Pod调整为规范的 desired state。反向操作(拆除)由 SyncTerminatingPod 和 SyncTerminatedPod 处理。
如果 SyncPod 无错误地退出,那么Pod运行时状态与期望的配置状态(Pod正在运行)同步。如果 SyncPod 以暂时性错误退出,那么下一次调用 SyncPod 预期会朝着达到期望状态的方向取得进展。当由于容器退出(对于 RestartNever 或 RestartOnFailure)而检测到Pod达到终端的生命周期阶段时,SyncPod 以 isTerminal 退出,并且下一个被调用的方法将是SyncTerminatingPod。如果Pod因任何其他原因终止,SyncPod 将收到上下文取消请求,应尽快退出。
func (kl *Kubelet) SyncPod(_ context.Context, updateType kubetypes.SyncPodType, pod, mirrorPod *v1.Pod, podStatus *kubecontainer.PodStatus) (isTerminal bool, err error) {}
参数解释:
updateType : 确定是否是创建(第一次)还是更新的类型,仅在度量指标中使用,因为此方法必须是可重入的
pod : 正在设置的Pod
mirrorPod : 该Pod的Kubelet已知的镜像Pod(如果有)
podStatus : 对该Pod观察到的最新Pod状态的描述,可用于确定在此次循环的 SyncPod 过程中应执行的操作集合
// The workflow is:
// – If the pod is being created, record pod worker start latency
// – Call generateAPIPodStatus to prepare an v1.PodStatus for the pod
// – If the pod is being seen as running for the first time, record pod
// start latency
// – Update the status of the pod in the status manager
// – Stop the pod’s containers if it should not be running due to soft
// admission
// – Ensure any background tracking for a runnable pod is started
// – Create a mirror pod if the pod is a static pod, and does not
// already have a mirror pod
// – Create the data directories for the pod if they do not exist
// – Wait for volumes to attach/mount
// – Fetch the pull secrets for the pod
// – Call the container runtime’s SyncPod callback
// – Update the traffic shaping for the pod’s ingress and egress limits
翻译过来
工作流程如下:
- 如果正在创建Pod,则记录Pod的启动延迟
- 调用
generateAPIPodStatus函数为Pod准备一个v1.PodStatus - 如果Pod 被认为是第一次运行,则记录Pod的启动延迟
- 更新Pod在
status manager中的状态 - 如果由于
soft admission准入而不应该运行Pod,则停止其容器 - 确保可运行Pod的任何后台追踪已启动
- 如果Pod是
static Pod且尚未具有mirror Pod,则创建mirrorPod - 如果Pod的数据目录不存在,则创建数据目录
- 等待卷的挂载
- Pod拉取密钥
- 调用容器运行时的
SyncPod回调函数, 真正创建Pod 的地方 - 更新Pod的入口和出口限制的流量
可以看到整个 SyncPod() 流程共分12个步骤。如果此工作流的任何步骤出错,则返回错误,并在下一次 SyncPod() 调用中重复此整个流程。
此操作写入调度的所有事件,以便提供有关错误情况的最准确信息,以帮助调试。如果此操作返回错误,则调用方不应写入事件
以上是我们根据注释而得知的信息,现在我们再看一下其源码实现。
// https://github.com/kubernetes/kubernetes/blob/v1.27.3/pkg/kubelet/kubelet.go#L1656
func (kl *Kubelet) SyncPod(_ context.Context, updateType kubetypes.SyncPodType, pod, mirrorPod *v1.Pod, podStatus *kubecontainer.PodStatus) (isTerminal bool, err error) {
var firstSeenTime time.Time
if firstSeenTimeStr, ok := pod.Annotations[kubetypes.ConfigFirstSeenAnnotationKey]; ok {
firstSeenTime = kubetypes.ConvertToTimestamp(firstSeenTimeStr).Get()
}
// 如果pod操作为create,则记录pod工作程序启动延迟
if updateType == kubetypes.SyncPodCreate {
metrics.PodWorkerStartDuration.Observe(metrics.SinceInSeconds(firstSeenTime))
}
// 根据pod和 status manager 生成最终 API pod status, 如果已是最终的状态,则直接中止操作
apiPodStatus := kl.generateAPIPodStatus(pod, podStatus, false)
...
// 如果Pod不应该运行,则请求将其容器停止
runnable := kl.canRunPod(pod)
if !runnable.Admit {
// Pod无法运行;并根据原因更新Pod和Container状态。
if apiPodStatus.Phase != v1.PodFailed && apiPodStatus.Phase != v1.PodSucceeded {
apiPodStatus.Phase = v1.PodPending
}
apiPodStatus.Reason = runnable.Reason
apiPodStatus.Message = runnable.Message
// Waiting containers are not creating.
const waitingReason = "Blocked"
for _, cs := range apiPodStatus.InitContainerStatuses {
if cs.State.Waiting != nil {
cs.State.Waiting.Reason = waitingReason
}
}
for _, cs := range apiPodStatus.ContainerStatuses {
if cs.State.Waiting != nil {
cs.State.Waiting.Reason = waitingReason
}
}
}
// 记录Pod变为 running 所花费的时间
existingStatus, ok := kl.statusManager.GetPodStatus(pod.UID)
if !ok || existingStatus.Phase == v1.PodPending && apiPodStatus.Phase == v1.PodRunning &&
!firstSeenTime.IsZero() {
metrics.PodStartDuration.Observe(metrics.SinceInSeconds(firstSeenTime))
}
// 在 status manager 中更新pod 状态
kl.statusManager.SetPodStatus(pod, apiPodStatus)
// 如果Pod不能运行则必须停止,并返回一个已知类型的错误给pod worker
if !runnable.Admit {
var syncErr error
// 将当前处于运行中的 container,组合成一个新的pod
p := kubecontainer.ConvertPodStatusToRunningPod(kl.getRuntime().Type(), podStatus)
if err := kl.killPod(ctx, pod, p, nil); err != nil {
syncErr = fmt.Errorf("error killing pod: %v", err)
utilruntime.HandleError(syncErr)
} else {
syncErr = fmt.Errorf("pod cannot be run: %s", runnable.Message)
}
return false, syncErr
}
}
如果当前Pod无法运行,则需要停止其所有containers 。首先调用 ConvertPodStatusToRunningPod() 将这个Pod里所有运行中的 containers 再组成一个新的Pod。然后再调用 k.killPod() 函数,通过 runtime( 在这里初始化) 将 kill 这个 pod 里的所有containers,通过跟踪发现底层调用的是 [killContainer()](https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/kuberuntime/kuberuntime_container.go#L702-L758) 函数。
// https://github.com/kubernetes/kubernetes/blob/v1.27.3/pkg/kubelet/kubelet.go#L1656
func (kl *Kubelet) SyncPod(_ context.Context, updateType kubetypes.SyncPodType, pod, mirrorPod *v1.Pod, podStatus *kubecontainer.PodStatus) (isTerminal bool, err error) {
// 网络插件未准备好(未安装cni插件,如 flannel、calico或cilium),且不是 host network ,则返回错误
if err := kl.runtimeState.networkErrors(); err != nil && !kubecontainer.IsHostNetworkPod(pod) {
return false, fmt.Errorf("%s: %v", NetworkNotReadyErrorMsg, err)
}
// kubelet知道pod引用了configMap 或 secret 资源
if !kl.podWorkers.IsPodTerminationRequested(pod.UID) {
if kl.secretManager != nil {
kl.secretManager.RegisterPod(pod)
}
if kl.configMapManager != nil {
kl.configMapManager.RegisterPod(pod)
}
}
// 为 Pod 创建Cgroup
pcm := kl.containerManager.NewPodContainerManager()
// 如果为 staticPod,则为其创建 mirrorPod
if kubetypes.IsStaticPod(pod) {...}
// 为Pod创建data 目录(每个pod都有自己三类目录 1. Pod目录 2.Volumes 目录 3.插件目录,其中volumes和 插件目录属于pod目录的子目录)
if err := kl.makePodDataDirs(pod); err != nil {}
// 为 Pod attach/mount volumes
if !kl.podWorkers.IsPodTerminationRequested(pod.UID) {
// Wait for volumes to attach/mount
if err := kl.volumeManager.WaitForAttachAndMount(pod); err != nil {
kl.recorder.Eventf(pod, v1.EventTypeWarning, events.FailedMountVolume, "Unable to attach or mount volumes: %v", err)
klog.ErrorS(err, "Unable to attach or mount volumes for pod; skipping pod", "pod", klog.KObj(pod))
return false, err
}
}
}
如果当前Pod 为 staticPod ,则删除其目前的 mirrorPod,后面再重新创建新的 mirrorPod。
为 Pod 创建相关目录,共三类目录,其中 volumes 目录和 plugins 目录属于 Pod目录的子目录。
同时为 pod 挂载 volumes 。
// Fetch the pull secrets for the pod
pullSecrets := kl.getPullSecretsForPod(pod)
// 为Pod添加Probe(最多三类探针:StartupProbe、ReadinessProbe、LivenessProbe, 每一类都启动一个goroutine来运行)
kl.probeManager.AddPod(pod)
为拉取 Pod镜像获取 secret,以便在 syncPod() 使用。
func (kl *Kubelet) getPullSecretsForPod(pod *v1.Pod) []v1.Secret {
pullSecrets := []v1.Secret{}
for _, secretRef := range pod.Spec.ImagePullSecrets {
if len(secretRef.Name) == 0 {
// API validation permitted entries with empty names (https://issue.k8s.io/99454#issuecomment-787838112).
// Ignore to avoid unnecessary warnings.
continue
}
secret, err := kl.secretManager.GetSecret(pod.Namespace, secretRef.Name)
if err != nil {
klog.InfoS("Unable to retrieve pull secret, the image pull may not succeed.", "pod", klog.KObj(pod), "secret", klog.KObj(secret), "err", err)
continue
}
pullSecrets = append(pullSecrets, *secret)
}
return pullSecrets
}
这里收集拉取镜像时使用的认证凭据,当我们部署需要从私有镜像仓库中拉取镜像 Pod 时,可以使用该字段来指定所需的认证凭据。
func (m *manager) AddPod(pod *v1.Pod) {
m.workerLock.Lock()
defer m.workerLock.Unlock()
key := probeKey{podUID: pod.UID}
for _, c := range pod.Spec.Containers {
key.containerName = c.Name
if c.StartupProbe != nil {
key.probeType = startup
...
w := newWorker(m, startup, pod, c)
m.workers[key] = w
go w.run()
}
if c.ReadinessProbe != nil {
key.probeType = readiness
...
w := newWorker(m, readiness, pod, c)
m.workers[key] = w
go w.run()
}
if c.LivenessProbe != nil {
key.probeType = liveness
...
w := newWorker(m, liveness, pod, c)
m.workers[key] = w
go w.run()
}
}
}
调用 [kl.probeManager.AddPod()](https://github.com/kubernetes/kubernetes/blob/v1.27.3/pkg/kubelet/prober/prober_manager.go#L169-L213) 为 Pod 添加探针,其实是针对Pod里的每一个 container 添加 probe。每个 container 最多有三类探针,分别为 StartupProbe、ReadinessProbe、和 LivenessProbe, 每一类都启动一个独立的goroutine来运行。
下面开始正式创建 Pod ,这也正是我们重点关注的地方
// Call the container runtime's SyncPod callback
result := kl.containerRuntime.SyncPod(ctx, pod, podStatus, pullSecrets, kl.backOff)
kl.reasonCache.Update(pod.UID, result)
if err := result.Error(); err != nil {
for _, r := range result.SyncResults {
if r.Error != kubecontainer.ErrCrashLoopBackOff && r.Error != images.ErrImagePullBackOff {
return false, err
}
}
return false, nil
}
这里 kl.containerRuntime.SyncPod() ``通过执行以下步骤将正在运行的pod同步到 desired 状态:
- Compute sandbox and container changes.
- Kill pod sandbox if necessary.
- Kill any containers that should not be running.
- Create sandbox if necessary. 调用函数
createPodSandbox()实现 - Create ephemeral containers. 对应
pod.Spec.EphemeralContainers字段 - Create init containers.
- Resize running containers (if InPlacePodVerticalScaling==true)
- Create normal containers. 对应
pod.Spec.Containers字段
上面的每一步都在源码里有注释,代码也比较的多,这里就不再一一介绍了,强烈推荐看一下其实现,因为它是创建Pod的核心逻辑。
一定要明白为什么需要先创建 sandbox ,后创建 container(这里是为了 hold 住network namespace)。
在创建 Pod 过程中,对于 sandbox 和 container 的操作均是通过调用 CRI 来实现的( 介绍),这里是以 [containerd](https://github.com/containerd/containerd) 这个运行时为例,实现 架构图 如下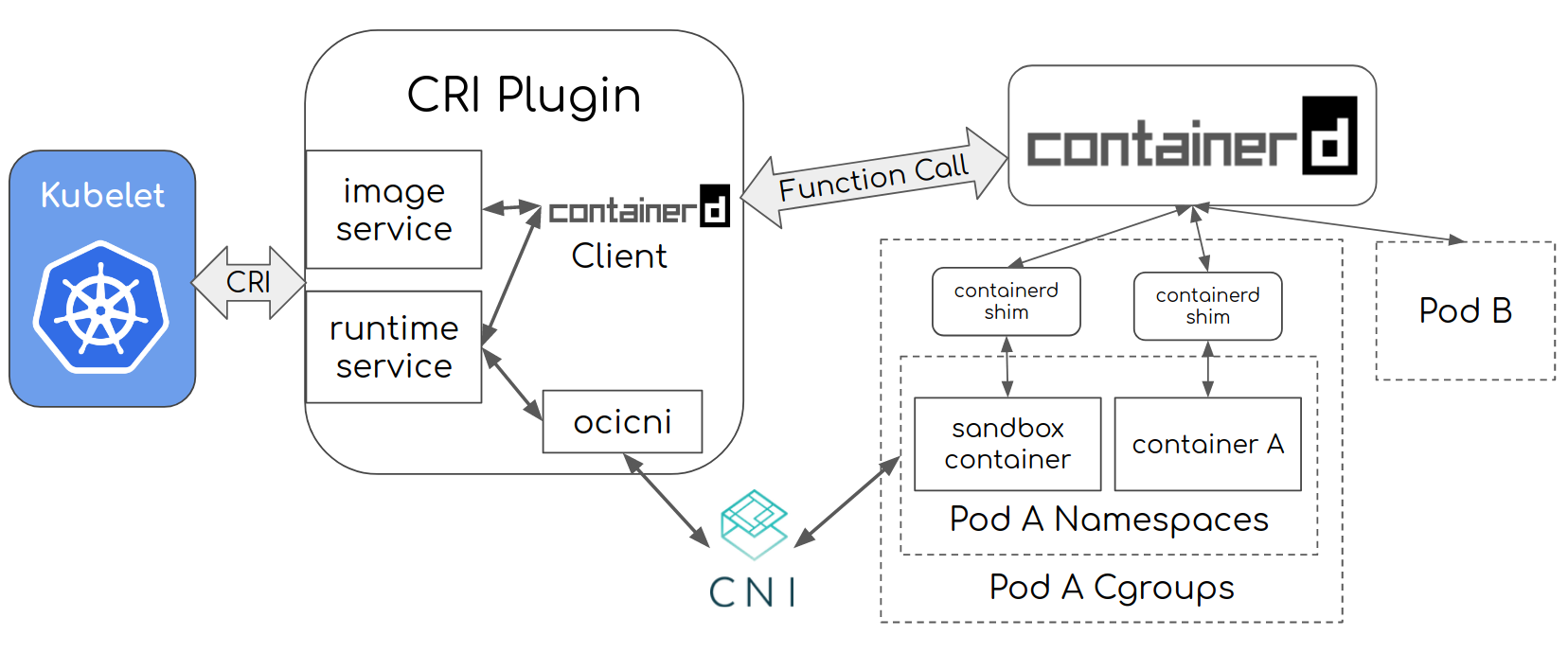
可以看到,在这里我们想做什么操作只需要 kubelet 调用 CRI 的 接口(gRPC客户端)就可以了,其真正的执行是由 CRI (containerd) 来完成的,而对于 CRI 来讲,其底层又是通过 OCI 调用 OS syscall 来实现的,整体流程见图。
containerd 实现代码见 https://github.com/containerd/containerd/blob/main/pkg/cri/server/sandbox_run.go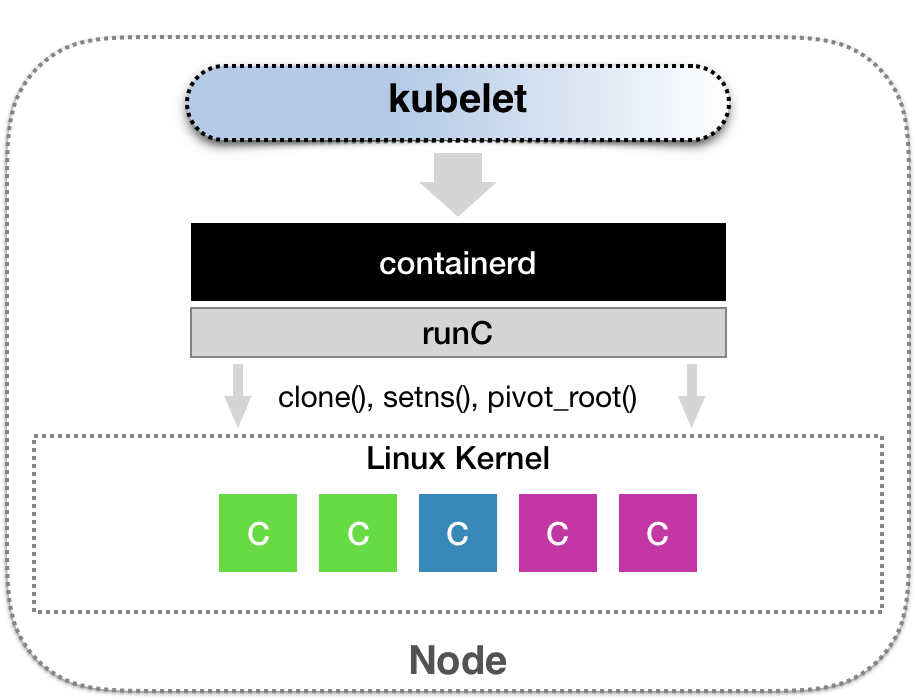
注意这里三类容器类型的先后顺序。
在上面八个步骤中的 start() 匿名函数里,通过调用 [startContainer()](https://github.com/kubernetes/kubernetes/blob/v1.27.3/pkg/kubelet/kuberuntime/kuberuntime_container.go#L170-L299) 实现了容器创建与启动,其整个过程分四步(重点关注):

- 拉取镜像,调用
m.imagePuller.EnsureImageExists()实现 - 创建容器,在此之前调用
m.internalLifecycle.PreCreateContainer() - 启动容器,在此之前调用
[m.internalLifecycle.PreStartContainer()](https://github.com/kubernetes/kubernetes/blob/v1.27.3/pkg/kubelet/kuberuntime/kuberuntime_container.go#L242) - 执行一些生命周期钩子(如果可能)
[m.runner.Run(ctx, kubeContainerID, pod, container, container.Lifecycle.PostStart)](https://github.com/kubernetes/kubernetes/blob/v1.27.3/pkg/kubelet/lifecycle/handlers.go#L70-L95)
以上就是创建Pod的基本流程了,对于其Pod的修改、删除 其流程都基本一样的,均是通过调用 CRI 接口来实现。
加入 workQueue 队列
在最后调用 p.completeWork() 将 pod 加入 workQueue()队列进行重试。
func (p *podWorkers) completeWork(podUID types.UID, phaseTransition bool, syncErr error) {
// Requeue the last update if the last sync returned error.
switch {
case phaseTransition:
p.workQueue.Enqueue(podUID, 0)
case syncErr == nil:
// No error; requeue at the regular resync interval.
p.workQueue.Enqueue(podUID, wait.Jitter(p.resyncInterval, workerResyncIntervalJitterFactor))
case strings.Contains(syncErr.Error(), NetworkNotReadyErrorMsg):
// Network is not ready; back off for short period of time and retry as network might be ready soon.
p.workQueue.Enqueue(podUID, wait.Jitter(backOffOnTransientErrorPeriod, workerBackOffPeriodJitterFactor))
default:
// Error occurred during the sync; back off and then retry.
p.workQueue.Enqueue(podUID, wait.Jitter(p.backOffPeriod, workerBackOffPeriodJitterFactor))
}
// 如果这是一个 pending update ,则直接添加到 workQueue队列,否则 status.working = false
p.podLock.Lock()
defer p.podLock.Unlock()
if status, ok := p.podSyncStatuses[podUID]; ok {
if status.pendingUpdate != nil {
select {
case p.podUpdates[podUID] <- struct{}{}:
klog.V(4).InfoS("Requeueing pod due to pending update", "podUID", podUID)
default:
klog.V(4).InfoS("Pending update already queued", "podUID", podUID)
}
} else {
status.working = false
}
}
}
这里的 p.workQueue 是 podWorker 中的一个的组件( 在这里初始化),它实现了一个简单 work queue。
podSyncer 组件
上面介绍过 p.podSyncer 属于 podWorker 的一个组件,主要用于同步pod 的 desired 状态。
它实现了 podSyncer 接口, 定义如下
// https://github.com/kubernetes/kubernetes/blob/v1.27.3/pkg/kubelet/pod_workers.go#L243-L270
type podSyncer interface {
SyncPod(ctx context.Context, updateType types.SyncPodType, pod *v1.Pod, mirrorPod *v1.Pod, podStatus *container.PodStatus) (bool, error)
SyncTerminatingPod(ctx context.Context, pod *v1.Pod, podStatus *container.PodStatus, gracePeriod *int64, podStatusFn func(*v1.PodStatus)) error
SyncTerminatingRuntimePod(ctx context.Context, runningPod *container.Pod) error
SyncTerminatedPod(ctx context.Context, pod *v1.Pod, podStatus *container.PodStatus) error
}
针对这四个方法我们这里介绍一下:
SyncPod: SyncPod 同步pod的配置,并且start 和 restarts pod 中的所有 containers。如果返回 true, 那么 pod 达到了最终状态, 而返回参数 error 表示成功或失败。如果 error != nil则表示同步失败,应该在未来重试。这是一个长时间运行的方法,应该与上下文一起提前退出。如果上下文被取消,则被取消。
SyncTerminatingPod: 试图确保pod的容器不再运行并收集任何最终状态。此方法会以递减的宽限期重复调用,直到它无错误的退出为止。
一旦此方法无错误的退出,则允许其他组件拆除 volumes 和设备等支持资源。如果上下文被取消,则该方法应返回上下文除非已成功完成,否则会被取消,当检测到较短的宽限期时可能会发生这种情况。
SyncTerminatingRuntimePod: 在发现与kubelet不再了解的Pod相对应的正在运行的容器时被调用,用于终止这些容器。除非所有的容器都已停止,否则它不应该无错误地退出。
SyncTerminatedPod: 在所有运行中的容器停止后被调用,负责释放那些应立即执行而不是在后台执行的资源。一旦它无错误地退出,该Pod在节点上被视为已完成。”
从上面可以看到,三种情况使用到了接口中定义的所有方法。
podSyncer描述了pod状态机的核心生命周期操作。
pod首先同步,直到它正常
termination(返回true)或者外部代理决定 terminated pod。一旦pod 变为
terminating就调用SyncTerminatingPod(),直到它没有返回错误为止。然后调用
SyncTerminatedPod()方法,直到它无错误地退出,并且该pod被视为终端。此接口的实现必须是线程安全的,以便同时调用多个pod的这些方法。
podManager 组件
podManager存储并管理对pod的访问,维护 static pod 和 mirror pod 之间的映射关系, 其数据结构 basicManager 为
type basicManager struct {
// Protects all internal maps.
lock sync.RWMutex
// Regular pods indexed by UID.
podByUID map[kubetypes.ResolvedPodUID]*v1.Pod
// Mirror pods indexed by UID.
mirrorPodByUID map[kubetypes.MirrorPodUID]*v1.Pod
// Pods indexed by full name for easy access.
podByFullName map[string]*v1.Pod
mirrorPodByFullName map[string]*v1.Pod
// Mirror pod UID to pod UID map.
translationByUID map[kubetypes.MirrorPodUID]kubetypes.ResolvedPodUID
// A mirror pod client to create/delete mirror pods.
MirrorClient // 对应 basicMirrorClient 对象
}
// pkg/kubelet/pod/mirror_client.go#L54
// 实现了 MirrorClient 接口
type basicMirrorClient struct {
apiserverClient clientset.Interface
nodeGetter nodeGetter
nodeName string
}
// MirrorClient knows how to create/delete a mirror pod in the API server.
type MirrorClient interface {
// CreateMirrorPod creates a mirror pod in the API server for the given
// pod or returns an error. The mirror pod will have the same annotations
// as the given pod as well as an extra annotation containing the hash of
// the static pod.
CreateMirrorPod(pod *v1.Pod) error
// DeleteMirrorPod deletes the mirror pod with the given full name from
// the API server or returns an error.
DeleteMirrorPod(podFullName string, uid *types.UID) (bool, error)
}
它实现了 Manager 接口。
type Manager interface {
GetPods() []*v1.Pod
GetPodByFullName(podFullName string) (*v1.Pod, bool)
GetPodByName(namespace string, name string) (*v1.Pod, bool)
GetPodByUID(types.UID) (*v1.Pod, bool)
GetPodByMirrorPod(*v1.Pod) (*v1.Pod, bool)
GetMirrorPodByPod(*v1.Pod) (*v1.Pod, bool)
GetPodsAndMirrorPods() ([]*v1.Pod, []*v1.Pod)
SetPods(pods []*v1.Pod)
AddPod(pod *v1.Pod)
UpdatePod(pod *v1.Pod)
DeletePod(pod *v1.Pod)
GetOrphanedMirrorPodNames() []string
TranslatePodUID(uid types.UID) types.ResolvedPodUID
GetUIDTranslations() (podToMirror map[types.ResolvedPodUID]types.MirrorPodUID, mirrorToPod map[types.MirrorPodUID]types.ResolvedPodUID)
IsMirrorPodOf(mirrorPod *v1.Pod, pod *v1.Pod) bool
MirrorClient
}
kubelet从三个来源发现pod Update: file(staticPod)、[http](https://github.com/kubernetes/kubernetes/blob/v1.27.3/pkg/kubelet/kubelet.go#L302-L306) 和 apiserver(kubeClient)。可以将来自非 apiserver 源的Pods称为 静态Pods。
通常情况下,Kubernetes API服务器负责创建和管理Pods(Regular pods),但静态Pods是由kubelet进程直接管理,API服务器不知道静态Pods的存在。为了监视这些Pod的状态,kubelet通过API服务器为每个 static Pod 创建一个 mirror Pod,以此间接实现对 Pod 的维护。
镜像pod与静态pod具有相同的pod全名(名称和命名空间)(尽管元数据不同,如UID等)。通过利用kubelet使用pod全名报告pod状态的事实,镜像pod的状态始终反映静态pod的实际状态。当静态pod被删除时,关联的镜像pod也将被删除。
静态Pods不受Kubernetes的高可用性机制的保护,如果运行静态Pods的节点发生故障,不会由Kubernetes自动将Pod重新调度到其他节点上。
要使用静态Pods,需要配置每个kubelet进程监视一个指定的目录,默认情况下,kubelet会在/etc/kubernetes/manifests目录下监视Pod配置文件。kubelet会周期性地检查这个目录,如果有新的Pod配置文件出现,kubelet就会创建对应的Pod。
静态Pods的配置文件与使用yaml或json格式的Pod描述文件相似,可以在配置文件中指定Pod的名称、容器的镜像、资源限制等信息。配置文件的示例如下:
apiVersion: v1
kind: Pod
metadata:
name: my-static-pod
spec:
containers:
- name: my-container
image: nginx:1.16
以上配置文件保存为/etc/kubernetes/manifests/static-pod.yaml,kubelet会读取并创建名为my-static-pod的Pod,其中包含一个名为my-container的容器,使用nginx:1.16镜像。
这里要注意 static Pod 与 mirror Pod 的区别。
总结
对于Pod 的操作需要两个组件,一个是 podManager 组件,另一个是 podWorker 组件。
其中 podManager 用来维护Pod的存放与读取,而 podWorker组件则是实现对 Pod 的同步操作。
对于 podWorker 会为每一个 pod 创建一个 pod worker goroutine,通过一个 Loop 来实现监听 podUpdate 信号(podWorkerLoop),一旦发生变更则通过 podWorker.podSyncer 组件来实现 pod 同步工作,如果有必要的话,将 podUID 添加到一个 work queue 队列,交给下一个相关组件来处理。
参考资料
- https://github.com/kubernetes/kubernetes/blob/v1.27.3/pkg/kubelet/kubelet.go
- https://github.com/kubernetes/kubernetes/blob/master/staging/src/k8s.io/cri-api/pkg/apis/runtime/v1/api.proto
- https://github.com/containerd/containerd/blob/main/pkg/cri/server/sandbox_run.go
- https://mp.weixin.qq.com/s/OWrDAT7vsVpLlrbntW4R4Q
- https://time.geekbang.org/column/article/71056
- https://time.geekbang.org/column/article/71499
- 临时容器ephemeral-containers