分布式存储 Ceph 介绍
admin
- 2 minutes read - 248 wordsCeph 是一个分布式存储系统,其广泛用于云平台,最常见的就是在 k8s 平台中,目前大部分云厂商都会选择 ceph 做为基础设施中的后端存储。
Ceph是高度可靠、易于管理和免费的。Ceph 的力量可以改变您公司的IT基础设施和管理大量数据的能力。Ceph提供了非凡的可扩展性——成千上万的客户端访问PB到EB的数据。Ceph节点利用商品硬件和智能守护进程,Ceph存储集群容纳大量节点,这些节点相互通信以动态复制和重新分发数据。
简介
对于一个 Ceph 集群至少需要一个 Ceph Monitor、一个 Ceph Manager 和 一个 Ceph OSDs(其个数决定了对象副本的个数)。
Ceph Metadata Server 是运行 Ceph 文件系统客户端所必需的。
最好的做法是为每个监视器配备一个Ceph管理器,但这不是必须的
Monitors
Ceph Monitor ( ceph-mon) 维护集群状态的映射,包括监视器映射、管理器映射、OSD 映射、MDS 映射和 CRUSH 映射。这些映射是 Ceph 守护进程相互协调所需的关键集群状态。监视器还负责管理守护进程和客户端之间的身份验证。
通常至少需要三个Monitors才能实现冗余和高可用性。
Ceph Manager
Ceph Manager (ceph-mgr) 负责跟踪运行时指标和 Ceph 集群的当前状态,包括存储利用率、当前性能指标和系统负载。Ceph Manager 守护进程还托管基于python的模块来管理和公开Ceph集群信息,包括基于web的 Ceph Dashboard 和 REST API。
通常至少需要两个 Manager 才能实现高可用性。
Ceph OSDs
一个对象存储守护程序(Ceph-OSD)存储数据,处理数据复制、恢复、再平衡,并通过检查其他 Ceph OSD 守护程序的心跳来向 Ceph Monitors 和 Ceph Manager 提供一些监控信息。
通常至少需要三个Ceph OSDs 来实现冗余和高可用性。
MDSs
Ceph Metadata Server (ceph-mds)代表Ceph File System 存储元数据(Ceph Block Device 和Ceph Object Storage 不使用MDS)。Ceph元数据服务器允许 POSIX 文件系统用户执行基本命令(如 ls、find等),而不会给Ceph存储集群带来巨大负担。
Ceph将数据作为对象存储在逻辑存储池中。使用 CRUSH 算法,Ceph计算哪个放置组(PG)应该包含对象,以及哪个OSD应该存储放置组(PG)。CRUSH 算法使Ceph存储集群能够动态扩展、重新平衡和恢复。
PG全称Placement Grouops,是一个逻辑的概念,一个PG包含多个OSD。引入PG这一层其实是为了更好的分配数据和定位数据。
架构
Ceph在一个统一的系统中独特地提供 Object、block 和 file 存储。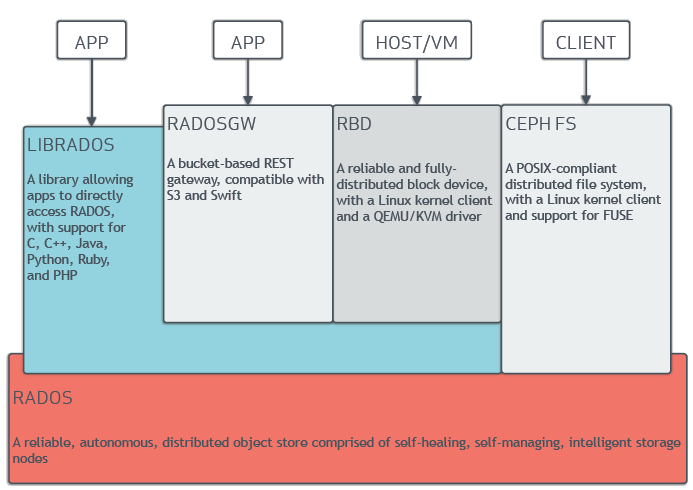
集群向外提供服务的四种方式:
Librados: 一个允许直接访问 RADOS的三方库,支持 C/C++/Java/Python/Ruby/PHP。
RADOSGW :是 RADOS GW 的简写, 可称为 RADOS 网关, 一个基于 RESET 风格的API接口,兼容 AWS S3 和 OpenStack Swift 协议,平时最常用的应该是 S3 协议。
RBD:全称RADOS block device,是Ceph对外提供的块设备服务。 一个可靠的分布式块设备,带有Linux内核客户端和 QEMU/KVM 驱动程序。
CEPH FS :全称Ceph File System,是Ceph对外提供的文件系统服务。兼容POSIX的分布式文件系统,具有linux内核客户端并支持FUSE。
这里的RADOS 全称 Reliable Autonomic Distributed Object Store,即可靠的自主分布式对象存储,它是Ceph集群的精华,用户实现数据分配、Failover等集群操作。
用户可以根据需求场景选择合适的客户端调用方式,如果使用的块设备,则需要使用RBD, 如果是WEB API的话,则应该首选 S3协议。
Ceph提供了一个基于 RADOS的无限可扩展的Ceph存储集群,您可以在 RADOS – A Scalable, Reliable Storage Service for Petabyte-scale Storage Clusters. 中了解到这一点。
集群客户端和每个 Ceph OSD 守护程序使用CRUSH算法来高效地计算有关数据位置的信息,而不必依赖于中央查找表。Ceph的高级功能包括通过 librados 到Ceph存储集群的 native interface,以及在librados之上构建的许多 service interfaces。
数据存储
Ceph存储集群从 Ceph Client 接收数据——无论是通过 Ceph Block Device、Ceph Object Storage、Ceph File System还是使用librados 创建的自定义实现——这些数据都存储为 RADOS对象。每个对象都存储在 Object Storage Device 上。
Ceph OSD守护程序处理 storage drives 上的 read、write 和 replication 操作。默认使用 BlueStore后端存储,对象以类似于数据库的方式存储。
Ceph OSD守护程序将数据作为对象存储在平面名称空间中(例如,没有目录层次结构)。对象具有identifier、binary data和由一组 name/value pairs组成的元数据。语义完全取决于Ceph客户端。例如,CephFS使用 metadata 来存储文件属性,例如文件所有者、创建日期、上次修改日期等等。
对象ID在整个集群中是唯一的,而不仅仅是在本地文件系统中。
以下是ChatGPT 对 BlueStore 存储的介绍
BlueStore是Ceph对象存储系统中的一种持久化存储后端,用于存储和管理对象数据。它是Ceph Luminous版本及以后版本引入的新的存储后端。相比于之前的存储后端(如FileStore和KeyValueStore),BlueStore提供了更好的性能和可伸缩性。
下面是一些关于BlueStore的特点和功能:
原生的存储引擎:BlueStore以原生的方式管理和存储对象数据,不依赖于底层文件系统。它使用RocksDB作为键值存储引擎,通过直接访问块设备(比如SSD)来存储数据。这样可以降低存取延迟和提高I/O吞吐量。
空间管理:BlueStore使用空间映射来管理对象数据的存储空间。它采用写时复制(Copy-on-Write)机制,允许多个写操作同时进行。这样可以避免文件系统的性能瓶颈和数据碎片问题。
压缩和消除冗余:BlueStore支持数据压缩和冗余消除,以减少数据占用的存储空间。它采用基于Btrfs的压缩算法来进行压缩,并使用块划分技术来寻找和去除冗余数据。
写缓存:BlueStore具有写缓存功能,可以将写请求缓存到内存中,然后异步将数据写入到持久化存储中。这种机制可以显著提高写操作的性能和吞吐量。
数据完整性:BlueStore通过在存储设备上使用Checksum的方式来确保数据的完整性。它会计算数据的校验和,并在读取时验证以确保数据没有被篡改。
总结起来,BlueStore是Ceph中一种高性能、可伸缩的持久化存储后端,提供了更好的I/O性能和存储效率。它通过直接访问块设备、空间管理、压缩和消除冗余等机制来提供出色的存储性能和数据完整性。
总结
本篇主要介绍了以下个知识点:
- 一个 Ceph 集群一般由哪几部分组成,每部分的职责分别是什么
- 一个客户端一般有哪几中方式访问Ceph集群服务(四种)
- 对于 对象存储器中对象的读、写和复制是由谁来处理的(OSD)
- 对象存储是放在一个
PG里的其中一个OSD内 - 一个数据对象在Ceph存储里是如何体现(标识符、二进制数据、多个键值对的元数据)
问题:
- Monitors 中有多个映射,这些映射是干什么的?
- 在集群中写和读一个对象时的底层实现逻辑是什么?
- 一个集群是如何实现高可用的?
- 如何搭建一个 Ceph 集群?
注:本篇文章只是为了让从未了解过Ceph存储的用户对其有个大概的认识,对于更深层次的详细内容可阅读官方文档.
参考资料
- https://docs.ceph.com/en/latest/start/intro/
- https://docs.ceph.com/en/latest/architecture/
- https://docs.ceph.com/en/latest/glossary/