kubernetes 网络中DNS解析原理
当我们通过域名(例如 www.example.com)访问一个网站时,第一步就是通过DNS服务器找到目的服务器IP地址(例如 93.184.215.14),接着再将请求数据包发送到这个 IP 服务器。
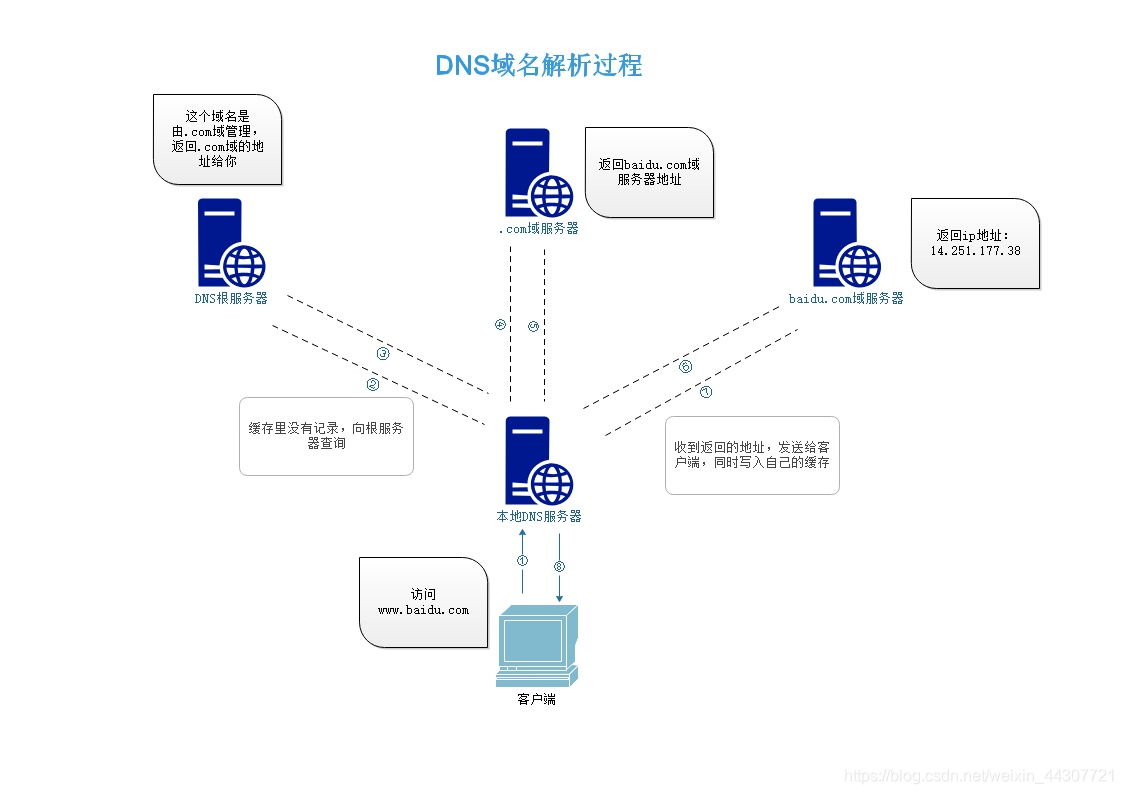
而要想通过 DNS 服务器进行域名,必须得先知道 DNS 服务器地址才行,而这一般是通过读取配置文件实现,在 *nux 操作系统中,DNS 服务器一般配置在 /etc/resolv.conf文件,如
search default.svc.cluster.local svc.cluster.local cluster.local
nameserver 10.96.0.10
options ndots:5
用户可以通过 nameserver 指定多个 DNS 服务器,依次对域名进行解析,如果解析成功,则解析操作立即中止,如果解析不到的话,则将回退到公网 DNS 服务器进行解析,这个公网 DNS 服务器一般是由网络运营商来定的,用户不需要关心。如果公网 DNS 仍解析失败的话,则直接响应域名无法解析,此时用户将无法正常访问域名。
什么是 FQDN
在介绍域名解析前,我们先了解一下什么是 FQDN。它是 Fully Qualified Domain Name 的缩写,中文称为 “完全限定域名”。
一个 FQDN 由以下部分组成:
- 主机名(Hostname): 如 www、mail、app 等,用于标识特定的主机或服务
- 域名(Domain Name): 如 example.com、company.org 等,用于标识特定的组织或网络域
- 根域(Root Domain): 表示为".“的根域,代表 DNS 域名层次结构的根
一个完整的 FQDN 看起来类似这样:
www.example.com.
注意最后的”.“表示根域的结尾。
FQDN 的作用是唯一地标识互联网上的主机名和域名。它能够避免由于域名冲突导致的解析歧义。例如,如果有 www.example.com 和 www.example.net 两个不同的域名,仅使用 www 是不够的,必须使用 FQDN 来精确指定。