Kubernetes集群扩缩容方案
- 7 minutes read - 1461 words动态扩缩容主要包括两个层级的动态扩缩容。一个层级是应用本身级别的扩缩容,如HPA、VPA。当应用负载过高时,可以通过HPA多部署几个Pods副本;或者通过VPA对当前Pod硬件资源进行扩容,以此来减少应用负载。
另一层是对集群自身的扩容,如 worker 节点的扩容。如部署Pods应用时,如果出现无可用节点资源可用时,则通过 Cluster Autoscaler 加入一些新的节点,并在新节点上重建Pods。
本文主要看一下应用这个层级的扩缩容方案。
水平扩展HPA && 垂直扩展VPA
HPA
在 Kubernetes 中,HPA(HorizontalPodAutoscaler)也称为水平扩缩容,它将根据当前应用程序工作负载,自动更新工作负载资源 (例如 Deployment 或者 StatefulSet)以满足当前需求。简单讲的话,就是如果集群检测到当前应用程序的n个Pod负载如果比较高的话,就再创建几个Pod副本,以减少当前负载,也就是我们平时说的水平扩容。相反如果应用程序Pod负载比较低的话,则将Pod副本数量进行减少,节省服务器资源,这个就是水平缩容。
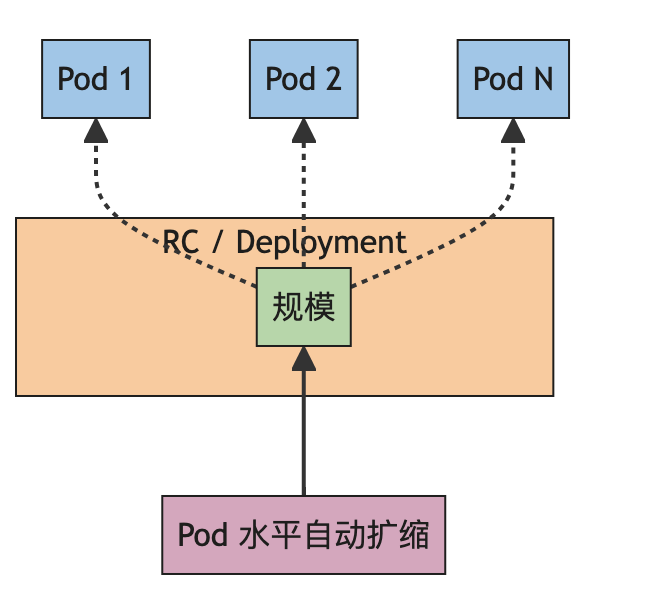
它的工作原理是这样的,集群控制器会定期(默认每 30 秒)查询目标资源的 Pod 的资源使用情况,并将其与 HPA 对象中指定的指标进行比较。如果资源使用情况超过或低于目标指标,HPA 控制器会根据扩缩容策略来扩缩容 Pod 数量。
Kubernetes 默认支持根据容器的 CPU 和内存的使用率。拿下面例子来说
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: web-app-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: web-app
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
targetAverageUtilization: 80
这里 scaleTargetRef 表示要操作的 Kind 对象 Deployment,其中副本最小数量为1,最大为10。而对条件的定义就是 metrics字段,这个示例里只指定了CPU,表示当 CPU 平均使用率达到80% 的时候就开始扩容。
可以看到其使用方法比较简单。
另外也可以对扩缩容行为进行定义,如
behavior:
scaleDown:
policies:
- type: Pods
value: 4
periodSeconds: 60
- type: Percent
value: 10
periodSeconds: 60
这里只对 scaleDown 缩容行为进行了定义,一共有两个策略。第一个策略(Pods)允许在一分钟内最多缩容 4 个副本,第二个策略(Percent) 允许在一分钟内最多缩容当前副本个数的百分之十。
periodSeconds 表示在过去的多长时间内要求策略值为真,你可以设置 periodSeconds 的最大值为 1800(半小时)。
现在 HPA 支持从其他的 API 中获取指标来进行扩容,HPA 控制器会从 apiservices 管理的 API 中获取一些指标,然后根据定义好指标的阈值来触发一些扩缩容。
$ kubectl get apiservices.apiregistration.k8s.io
NAME SERVICE AVAILABLE AGE
v1beta1.custom.metrics.k8s.io monitoring/prometheus-adapter True 30h
v1beta1.external.metrics.k8s.io addons-system/keda-operator-metrics-apiserver True 5h37m
v1beta1.metrics.k8s.io kube-system/metrics-server True 26d
对于资源指标,使用 metrics.k8s.io API, 一般由 metrics-server 提供。 它可以作为集群插件启动。
对于自定义指标,使用 custom.metrics.k8s.io API。 它由其他“适配器(Adapter)” API 服务器提供。从上面的命令输出可以看出,这里是由 prometheus-adapter 来提供的。
对于外部指标,将使用 external.metrics.k8s.io API。
其中 Prometheus-Adapter 是一款用于将 Prometheus 指标转换为 Kubernetes 自定义指标的工具。它可以用于将 Prometheus 监控的应用程序的指标暴露给 Kubernetes Horizontal Pod Autoscaler (HPA) 等工具。
工作经历三个阶段:
- Prometheus-Adapter 会定期(默认每 30 秒)从 Prometheus 服务器拉取指标数据。
- Prometheus-Adapter 会将拉取到的指标数据转换为 Kubernetes API Server 可以理解的形式。
- Prometheus-Adapter 会将转换后的指标数据暴露给 Kubernetes API Server。
从上面这三个阶段可以看出HPA方案有存在一个很大的缺点,那就是K8S集群无法实时根据负载情况动态扩缩容,存在一定的延时(默认30秒)。
VPA
上面我们介绍了HPA以及其应用场景和缺点,这里我们再看一下VPA(Vertical Pod Autoscaler),以及其适合的场景有哪些?
上面我们已说过VPA 可以理解为对单个服务资源进行扩容,如CPU、内存之类。它一般应用于一些中心化的单体应用,且无法对其进行部署多份副本的场景,如 Prometheus 或 Jenkins 这类的应用。
当控制器检测到一个Pod负载过高时,这时会对当前Pod进行终止,接着对Pod的CPU或内存进行扩容,最后重建Pod,此时Pod可能在任何一个节点进行重建。
可以看到它与HPA的扩容机制是完全不一样的,VPA扩容过程中将无法正常提供服务,也因此它使用的场景相比HPA来说,要少的多。
总结
对于HPA和VPA,它的扩缩容都需要从其它地方进行一些指标信息的读取,而这些指标的信息又是定期采集的,因此每次进行扩缩容时总是出现慢半拍的延时问题。
如果要解决这个问题,我们可能需要一款基于事件驱动的扩容方案。
基于事件驱动的KEDA方案
KEDA(Kubernetes Event-driven Autoscaling) 是2019 年 11 月由微软发布的基于事件驱动型的应用程序扩缩容工具,它的设计机制与HPA完全不一样的。
本文不打算对其进行详细的介绍,有兴趣的话可参考官方文档 https://keda.sh/docs/2.13/deploy/,这里只做一些概括总结。
架构
下图显示了 KEDA 如何与 Kubernetes Horizontal Pod Autoscaler、外部事件源和 Kubernetes 的 etcd 数据存储结合使用。
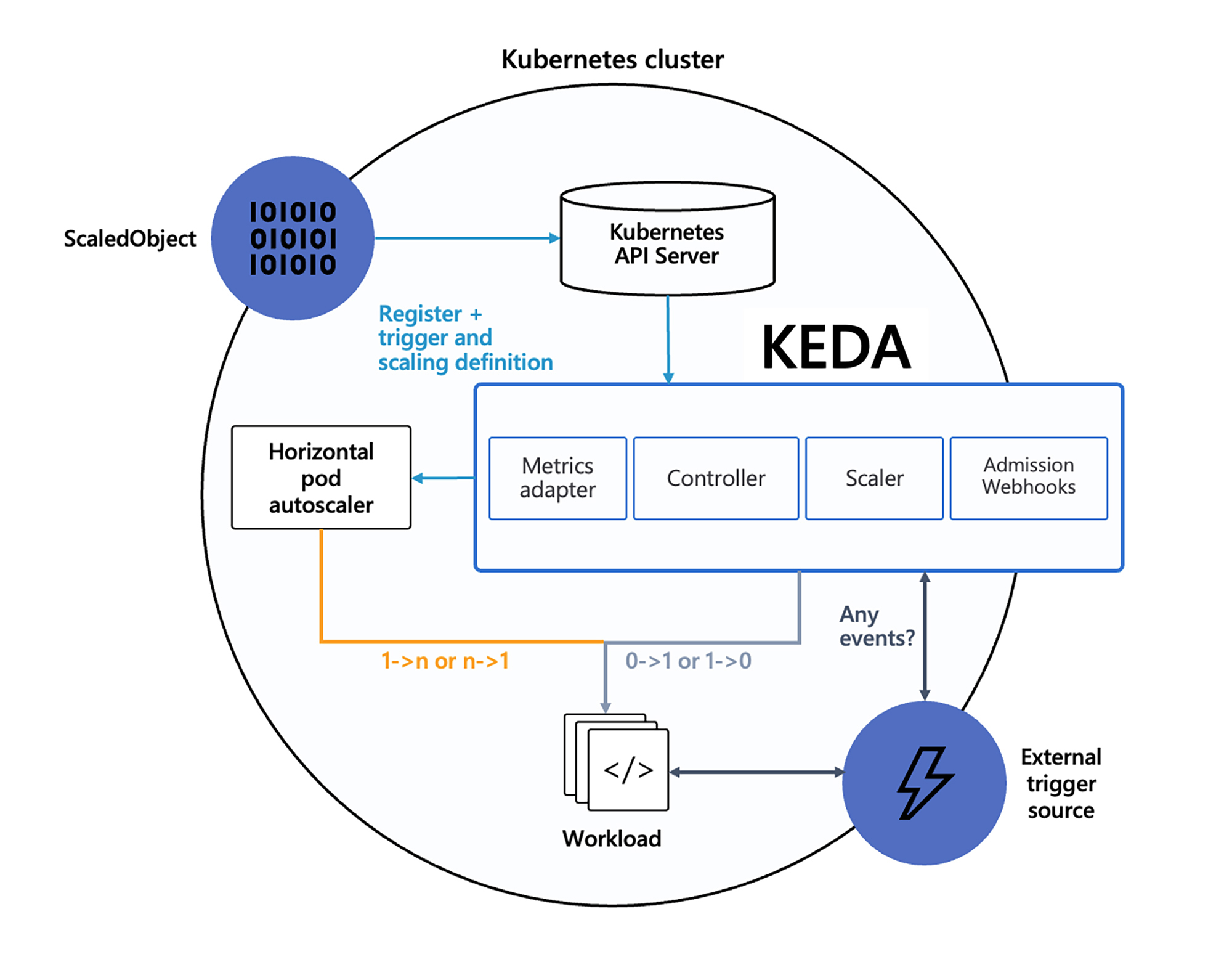
主要由以下几个部分组成:
ScaledObject 它是 KEDA 自定义对象CRD。用于定义自动伸缩的规则和目标。它可以用来定义触发器类型(例如 RabbitMQ、Kafka 等)、触发器元数据、最小和最大副本数等参数。
External trigger source 事件源。支持多种事件源,例如 HTTP 请求、消息队列消息、数据库连接等。当事件源产生新的事件时,KEDA 会自动触发自动伸缩。
Scaler 接收事件并将其转换为 Kubernetes 可以理解的格式,然后根据 ScaledObject 定义的规则决定是否需要进行伸缩。
Metrics Adapter 是 KEDA 与 Kubernetes HPA(Horizontal Pod Autoscaler)之间的桥梁,用于将 Scaler 查询到的事件数量转化为 Kubernetes HPA 可以理解的度量值。
Event Sources 和 Scalers
KEDA有一系列的缩放器,既可以检测是否应该激活或停用部署,也可以为特定的事件源提供自定义度量。支持的i常见缩放器有 ActiveMQ、Kafka、RabbitMQ、ETCD、MongoDB、MySQL、MSSQL、Redis、Prometheus、elasticsearch等,更多缩放器见 https://keda.sh/docs/2.14/concepts/#event-sources-and-scalers
Custom Resources (CRD)
参考文档https://keda.sh/docs/2.14/deploy/部署KEDA,将自动安装以下四个 CRD
scaledobjects.keda.shscaledjobs.keda.shtriggerauthentications.keda.shclustertriggerauthentications.keda.sh
这些自定义资源使您能够将事件源(以及对该事件源的身份验证)映射到 Deployment、StatefulSet、 Custom Resource 或 Job 以进行扩缩容。
ScaledObjects表示event sources(例如 Rabbit MQ)与 Kubernetes Deployment、StatefulSet 或 任何定义了/scale子资源的 Custom Resource 之间所需的映射。ScaledObject specscaledobject_types.goapiVersion: keda.sh/v1alpha1 kind: ScaledObject metadata: name: {scaled-object-name} annotations: scaledobject.keda.sh/transfer-hpa-ownership: "true" # Optional. Use to transfer an existing HPA ownership to this ScaledObject validations.keda.sh/hpa-ownership: "true" # Optional. Use to disable HPA ownership validation on this ScaledObject autoscaling.keda.sh/paused: "true" # Optional. Use to pause autoscaling of objects explicitly spec: scaleTargetRef: apiVersion: {api-version-of-target-resource} # Optional. Default: apps/v1 kind: {kind-of-target-resource} # Optional. Default: Deployment name: {name-of-target-resource} # Mandatory. Must be in the same namespace as the ScaledObject envSourceContainerName: {container-name} # Optional. Default: .spec.template.spec.containers[0] pollingInterval: 30 # Optional. Default: 30 seconds cooldownPeriod: 300 # Optional. Default: 300 seconds idleReplicaCount: 0 # Optional. Default: ignored, must be less than minReplicaCount minReplicaCount: 1 # Optional. Default: 0 maxReplicaCount: 100 # Optional. Default: 100 fallback: # Optional. Section to specify fallback options failureThreshold: 3 # Mandatory if fallback section is included replicas: 6 # Mandatory if fallback section is included advanced: # Optional. Section to specify advanced options restoreToOriginalReplicaCount: true/false # Optional. Default: false horizontalPodAutoscalerConfig: # Optional. Section to specify HPA related options name: {name-of-hpa-resource} # Optional. Default: keda-hpa-{scaled-object-name} behavior: # Optional. Use to modify HPA's scaling behavior scaleDown: stabilizationWindowSeconds: 300 policies: - type: Percent value: 100 periodSeconds: 15 triggers: # {list of triggers to activate scaling of the target resource} # ref: https://keda.sh/docs/2.14/scalers/对 ScaledObject 介绍参考 https://keda.sh/docs/2.14/concepts/scaling-deployments/#scaling-of-custom-resources
ScaledJobs表示event sources和 Kubernetes Job 之间的映射。ScaledJob specscaledjob_types.goapiVersion: keda.sh/v1alpha1 kind: ScaledJob metadata: name: {scaled-job-name} labels: my-label: {my-label-value} # Optional. ScaledJob labels are applied to child Jobs annotations: autoscaling.keda.sh/paused: true # Optional. Use to pause autoscaling of Jobs my-annotation: {my-annotation-value} # Optional. ScaledJob annotations are applied to child Jobs spec: jobTargetRef: parallelism: 1 # [max number of desired pods](https://kubernetes.io/docs/concepts/workloads/controllers/job/#controlling-parallelism) completions: 1 # [desired number of successfully finished pods](https://kubernetes.io/docs/concepts/workloads/controllers/job/#controlling-parallelism) activeDeadlineSeconds: 600 # Specifies the duration in seconds relative to the startTime that the job may be active before the system tries to terminate it; value must be positive integer backoffLimit: 6 # Specifies the number of retries before marking this job failed. Defaults to 6 template: # describes the [job template](https://kubernetes.io/docs/concepts/workloads/controllers/job) pollingInterval: 30 # Optional. Default: 30 seconds successfulJobsHistoryLimit: 5 # Optional. Default: 100. How many completed jobs should be kept. failedJobsHistoryLimit: 5 # Optional. Default: 100. How many failed jobs should be kept. envSourceContainerName: {container-name} # Optional. Default: .spec.JobTargetRef.template.spec.containers[0] minReplicaCount: 10 # Optional. Default: 0 maxReplicaCount: 100 # Optional. Default: 100 rolloutStrategy: gradual # Deprecated: Use rollout.strategy instead (see below). rollout: strategy: gradual # Optional. Default: default. Which Rollout Strategy KEDA will use. propagationPolicy: foreground # Optional. Default: background. Kubernetes propagation policy for cleaning up existing jobs during rollout. scalingStrategy: strategy: "custom" # Optional. Default: default. Which Scaling Strategy to use. customScalingQueueLengthDeduction: 1 # Optional. A parameter to optimize custom ScalingStrategy. customScalingRunningJobPercentage: "0.5" # Optional. A parameter to optimize custom ScalingStrategy. pendingPodConditions: # Optional. A parameter to calculate pending job count per the specified pod conditions - "Ready" - "PodScheduled" - "AnyOtherCustomPodCondition" multipleScalersCalculation : "max" # Optional. Default: max. Specifies how to calculate the target metrics when multiple scalers are defined. triggers: # {list of triggers to create jobs} # ref: https://keda.sh/docs/2.14/scalers/ScaledObject/ScaledJob通过引用TriggerAuthentication或ClusterTriggerAuthentication,其中包含用于监视事件源的身份验证配置或secret。介绍文档参考 https://keda.sh/docs/2.14/concepts/authentication/有时候对于一些敏感信息我们可能需要进行加密,如果使用 RabbitMQ 缩放器 ,则该
host参数可能包含密码,因此需要作为参考。可以使用host字符串的值创建机密,在部署中引用该机密,并将其映射到ScaledObject元数据参数,如下所示:apiVersion: v1 kind: Secret metadata: name: {secret-name} data: {secret-key-name}: YW1xcDovL3VzZXI6UEFTU1dPUkRAcmFiYml0bXEuZGVmYXVsdC5zdmMuY2x1c3Rlci5sb2NhbDo1Njcy #base64 encoded per secret spec --- apiVersion: apps/v1 kind: Deployment metadata: name: {deployment-name} namespace: default labels: app: {deployment-name} spec: selector: matchLabels: app: {deployment-name} template: metadata: labels: app: {deployment-name} spec: containers: - name: {deployment-name} image: {container-image} envFrom: - secretRef: name: {secret-name} --- apiVersion: keda.sh/v1alpha1 kind: ScaledObject metadata: name: {scaled-object-name} namespace: default spec: scaleTargetRef: name: {deployment-name} triggers: - type: rabbitmq metadata: queueName: hello host: {secret-key-name} queueLength : '5'上面 ScaledObject 使用的 event sources 为 rabbitmq,并指定了queueName、host 和 queueLength。
但这种用法存在一些缺点,见 https://keda.sh/docs/2.14/concepts/authentication/#the-downsides
出于这些原因和其他原因,我们还提供了一个
TriggerAuthentication资源,用于将身份验证定义为ScaledObject。这允许您直接引用密钥、配置为使用 Pod 身份或使用由其他团队管理的身份验证对象。TriggerAuthentication允许您描述独立ScaledObject于部署容器的身份验证参数。它还支持更高级的身份验证方法,例如“pod 身份”、身份验证重用或允许 IT 配置身份验证。apiVersion: keda.sh/v1alpha1 kind: TriggerAuthentication metadata: name: {trigger-authentication-name} namespace: default # must be same namespace as the ScaledObject spec: podIdentity: provider: none | azure | azure-workload | aws | aws-eks | aws-kiam | gcp # Optional. Default: none identityId: <identity-id> # Optional. Only used by azure & azure-workload providers. roleArn: <role-arn> # Optional. Only used by aws provider. identityOwner: keda|workload # Optional. Only used by aws provider. secretTargetRef: # Optional. - parameter: {scaledObject-parameter-name} # Required. name: {secret-name} # Required. key: {secret-key-name} # Required. env: # Optional. - parameter: {scaledObject-parameter-name} # Required. name: {env-name} # Required. containerName: {container-name} # Optional. Default: scaleTargetRef.envSourceContainerName of ScaledObject hashiCorpVault: # Optional. address: {hashicorp-vault-address} # Required. namespace: {hashicorp-vault-namespace} # Optional. Default is root namespace. Useful for Vault Enterprise authentication: token | kubernetes # Required. role: {hashicorp-vault-role} # Optional. mount: {hashicorp-vault-mount} # Optional. credential: # Optional. token: {hashicorp-vault-token} # Optional. serviceAccount: {path-to-service-account-file} # Optional. secrets: # Required. - parameter: {scaledObject-parameter-name} # Required. key: {hashicorp-vault-secret-key-name} # Required. path: {hashicorp-vault-secret-path} # Required. azureKeyVault: # Optional. vaultUri: {key-vault-address} # Required. podIdentity: # Optional. Required when using pod identity. provider: azure | azure-workload # Required. identityId: <identity-id> # Optional credentials: # Optional. Required when not using pod identity. clientId: {azure-ad-client-id} # Required. clientSecret: # Required. valueFrom: # Required. secretKeyRef: # Required. name: {k8s-secret-with-azure-ad-secret} # Required. key: {key-within-the-secret} # Required. tenantId: {azure-ad-tenant-id} # Required. cloud: # Optional. type: AzurePublicCloud | AzureUSGovernmentCloud | AzureChinaCloud | AzureGermanCloud | Private # Required. keyVaultResourceURL: {key-vault-resource-url-for-cloud} # Required when type = Private. activeDirectoryEndpoint: {active-directory-endpoint-for-cloud} # Required when type = Private. secrets: # Required. - parameter: {param-name-used-for-auth} # Required. name: {key-vault-secret-name} # Required. version: {key-vault-secret-version} # Optional. awsSecretManager: podIdentity: # Optional. provider: aws # Required. credentials: # Optional. accessKey: # Required. valueFrom: # Required. secretKeyRef: # Required. name: {k8s-secret-with-aws-credentials} # Required. key: AWS_ACCESS_KEY_ID # Required. accessSecretKey: # Required. valueFrom: # Required. secretKeyRef: # Required. name: {k8s-secret-with-aws-credentials} # Required. key: AWS_SECRET_ACCESS_KEY # Required. region: {aws-region} # Optional. secrets: # Required. - parameter: {param-name-used-for-auth} # Required. name: {aws-secret-name} # Required. version: {aws-secret-version} # Optional. gcpSecretManager: # Optional. secrets: # Required. - parameter: {param-name-used-for-auth} # Required. id: {secret-manager-secret-name} # Required. version: {secret-manager-secret-name} # Optional. podIdentity: # Optional. provider: gcp # Required. credentials: # Optional. clientSecret: # Required. valueFrom: # Required. secretKeyRef: # Required. name: {k8s-secret-with-gcp-iam-sa-secret} # Required. key: {key-within-the-secret}在定义中
TriggerAuthentication定义的每个参数都不需要包含在ScaledObject定义的触发器中metadata。若要从ScaledObject引用TriggerAuthentication,请将添加到authenticationRef触发器中。# some Scaled Object # ... triggers: - type: {scaler-type} metadata: param1: {some-value} authenticationRef: name: {trigger-authentication-name} # this may define other params not defined in metadata每个
TriggerAuthentication都定义在一个命名空间中,并且只能由同一命名空间中的 aScaledObject使用。如果要在多个命名空间中的缩放器之间共享一组凭据,则可以改为ClusterTriggerAuthentication创建一个 .作为全局对象,可以从任何命名空间使用它。若要将触发器设置为使用ClusterTriggerAuthentication,请向身份验证引用添加一个kind字段:authenticationRef: name: {cluster-trigger-authentication-name} kind: ClusterTriggerAuthentication定义
ClusterTriggerAuthentication的工作方式几乎与TriggerAuthentication相同,只是没有metadata.namespace值:apiVersion: keda.sh/v1alpha1 kind: ClusterTriggerAuthentication metadata: name: {cluster-trigger-authentication-name} spec: # As before ...
它的优势
扩缩容机制灵活
KEDA 可以根据应用的实际负载进行扩缩容,而不是依赖于 CPU 或内存等资源指标。KEDA 还可以根据负载的阶梯变化来扩缩容 Pod。例如,当负载增加 10% 时,KEDA 可以扩容 1 个 Pod。当负载增加 20% 时,KEDA 可以再扩容 2 个 Pod。 事件驱动可以根据应用程序的具体事件进行扩缩容,而指标驱动只能根据预定义的指标进行扩缩容。
扩缩容速度快
与基于指标驱动的 Prometheus-Adapter 不同,KEDA 无需等待指标收集就能立即响应事件,从而快速扩缩容 Pod,这可以进一步缩短扩缩容的响应时间。而 Prometheus-Adapter 需要等待 Prometheus 定期收集指标数据,然后才能根据指标数据触发 Pod 的扩缩容,这意味着 KEDA 可以更快地应对突发负载,避免服务中断。
资源利用率高 KEDA 利用了 Predictkube 这个 AI-Base 的 Kubernetes 扩容插件。 PredictKube 插件可以使用 Prometheus 历史数据来预测未来的负载,并提前扩容 Pod,以确保应用始终有足够的资源来处理负载,避免资源浪费或不足。
实验
参考官方实例 https://github.com/kedacore/sample-go-rabbitmq,event sources 采用 rabbitmq, scale 对象为 rabbitMQ Consume
总结
本文我们分别介绍了基于指标驱动的 HAP&VPA 和 基于事件驱动的 KEDA 两种扩缩容解决方案,具体采用哪一种方案则需要根据实现情况而定。
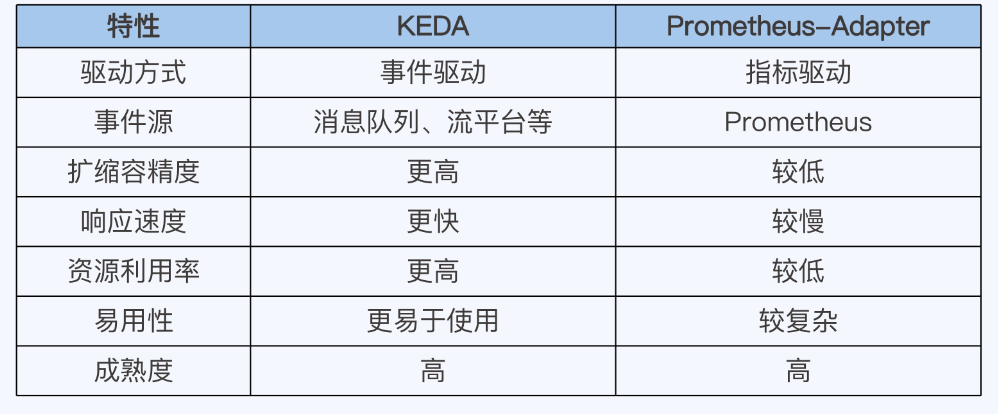
选择 KEDA 还是 Prometheus-Adapter,取决于我们的具体需求。
- 如果你的应用是事件驱动的,则 KEDA 是更好的选择。
- 如果你的应用是指标驱动的,则 Prometheus-Adapter 是更好的选择。
- 如果你需要更精准的扩缩容和更快的响应速度,则 KEDA 是更好的选择。
区别图表
另外上面提到的扩容方案都是基于应用情况实时进行扩容的,对于一些应用如果我们知道其高负载的时间点,能否提前进行“预扩缩容”呢?如外卖应用,一般在11:30 - 12:30 是下单的高峰期,我们能否在其之前或之后进行动态的扩容和缩容呢?这时不防了解一下阿里云给的定时扩缩容方案 https://github.com/AliyunContainerService/kubernetes-cronhpa-controller
参考资料
- https://kubernetes.io/zh-cn/docs/tasks/run-application/horizontal-pod-autoscale/
- https://keda.sh/
- https://github.com/kedacore/keda
- https://time.geekbang.org/column/article/768082
- https://github.com/AliyunContainerService/kubernetes-cronhpa-controller
- https://github.com/kedacore/samples