如何实现访问k8s集群服务之原理
- 5 minutes read - 873 words当我们想将 k8s 集群里的服务向外暴露时,一般是将 k8s service 指定 LoadBalancer类型。目前大多数云厂商会绑定云平台的负载均衡器,并为其分配一个固定的公网 IP 从而向外提供服务。而对于我们自建的 kubernetes 裸机集群则只能选择类似 MetalLB 这类解决方案,这种情况下如何让用户可以通过这个 IP 访问到自建 k8s 的服务呢,本文来分析一下其实现原理。
本文的环境安装了 MetallB,它指定分配 IP Pool 为内网 IP 地址,实验环境为 https://blog.haohtml.com/posts/install-kubernetes-in-raspberry-pi/。
将外部请求流入集群节点
当我们需要访问一台机器时,无论是使用 IP 地址还是域名,最终都需要将其解析为 IP 地址。而要真正建立连接并传输数据,我们必须获取目标 IP 地址对应的 MAC 地址,这是由于 TCP/IP 协议分层机制决定的。
在 TCP/IP 协议栈的链路层,数据是通过封装成数据帧的方式在局域网内传输的。数据帧中包含了目标 MAC 地址,用于标识应该将数据发送到哪个网络设备。因此,如果我们想要与某台机器建立通信,就必须首先知道其 IP 地址对应的 MAC 地址。
而 ARP 协议正是解决这一问题的利器。它通过在局域网内广播 ARP 请求,询问拥有某 IP 地址的主机的 MAC 地址。拥有该 IP 地址的目标主机会作出 ARP 响应,将自身的 IP 地址和 MAC 地址映射关系回复给发送方。发送方就可以基于这个映射关系,构建含有正确目标 MAC 地址的数据帧,并最终通过物理网络将数据传输到目的地。
搞明白了一点,理解起来就简单多了。
这里先贴一下实验环境,k8s master 节点 ip 配置
$ ifconfig eth0
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.1.101 netmask 255.255.255.0 broadcast 192.168.1.255
inet6 fe80::e65f:1ff:fe56:9ac9 prefixlen 64 scopeid 0x20<link>
ether e4:5f:01:56:9a:c9 txqueuelen 1000 (Ethernet)
RX packets 201847 bytes 54371842 (54.3 MB)
RX errors 0 dropped 1391 overruns 0 frame 0
TX packets 212472 bytes 102339632 (102.3 MB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
这里 IP 地址为 192.168.1.101, 其对应的 MAC 地址为 e4:5f:01:56:9a:c9, 也就是说当用户访问 192.168.1.101 的时候,流量会到达 MAC 为 e4:5f:01:56:9a:c9机器。
当我们安装完 MetallB 后,会有一个 Speaker 组件对 LoadBalancer IP 发起相应的广播或应答。
ARP 流程:
- 用户首次访问这个 IP 时,会先检查 ARP 缓存是否在此对应的 MAC 记录,此时肯定是不存在记录的,则本机以广播的方式发送给本地网段内的所有主机。
- 所有收到此广播的机器收到后检查本机是持有此 IP 地址,如果有的话则进行 ARP 响应,响应数据包中包含自身的 IP 地址和 MAC 地址映射关系。
- 然后发起请求的机器收到响应,将将此 IP 与 MAC 映射成一条 ARP 记录,并在本地进行一段时间的缓存,这样下次访问时直接从缓存中读取此记录。
$ arp -a
? (192.168.1.1) at 9c:7f:81:e:30:fc on en0 ifscope [ethernet]
? (192.168.1.100) at 5c:2:14:d5:ca:e2 on en0 ifscope [ethernet]
? (192.168.1.101) at e4:5f:1:56:9a:c9 on en0 ifscope [ethernet]
? (192.168.1.150) at e4:5f:1:56:a5:19 on en0 ifscope [ethernet]
? (192.168.1.200) at e4:5f:1:56:9a:c9 on en0 ifscope [ethernet]
可以看到其对应的 MAC 也是 e4:5f:1:56:9a:c9, 也就是说访问 192.168.1.101或 192.168.1.200 时,流量都将到达同一个服务器。
$ kubectl get svc -n ingress-nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx-controller LoadBalancer 10.103.50.74 192.168.1.200 80:32628/TCP,443:31948/TCP 12d
ingress-nginx-controller-admission ClusterIP 10.100.134.238 <none> 443/TCP 12d
arp 记录有一个有效期,如果长时间不访问此记录将从本机删除掉,对于普通的服务器绑定的真实 IP 来讲,这条记录会经常通过 ARP 进行局域网广播(因为其服务器都存在一些服务与局域网进行通讯),但对于 LoadBalancer IP 它是一个虚拟 IP 地址,此 IP 没有任何服务,因此只有用户访问此 IP 时才会产生 ARP 记录。 如果使用
ping 192.168.1.200的话,则不会有响应,因它这是一个虚拟 IP
将节点流量流入集群
好了,现在已经让用户访问 IP 的流量流入到了我们的 master 节点,剩下的一个问题就是如何再将这些流量流入到集群内部到真正提供服务的 POD。
这里直接给出结论,主要是通过 iptables 来实现(准确的说是通过 netfilter 实现),其用到了 iptable 四表五链中的 NAT 表。我们先看一下 iptables flow 过程
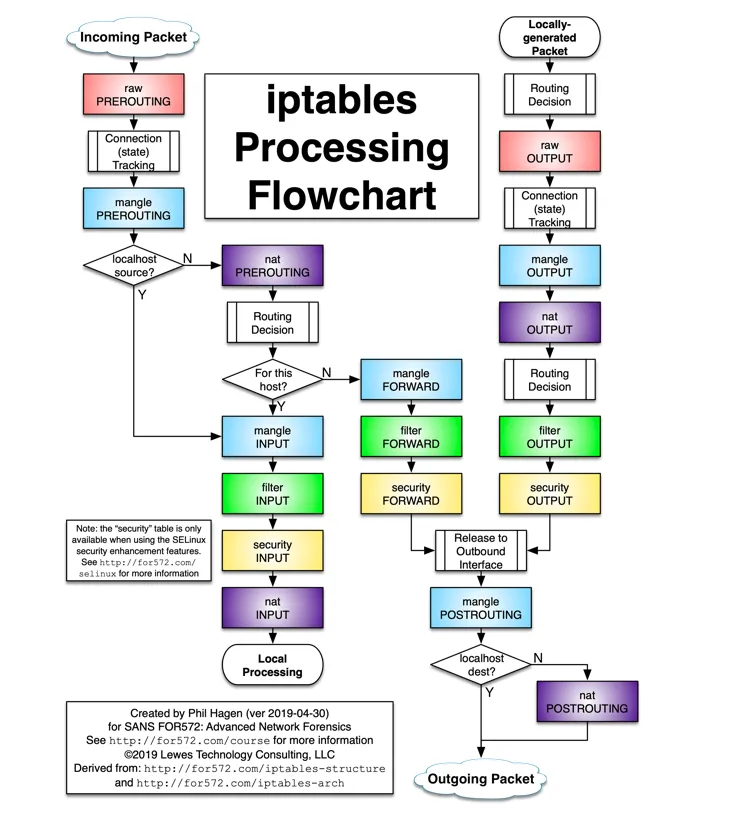
根据数据包的来源,可分为 “Incoming Packet” 和 “Locally-generated Packet”, 两者的区别已经在 https://blog.haohtml.com/archives/31967/ 介绍过了。
对于不同来源的数据包都需要做相应的处理,如果是"Incoming Packet"数据包,则在 PREROUTING 链中处理;而对于 “Locally-generated Packet"数据包,则在 OUTPUT 链中处理。
Chain PREROUTING (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
5023 614K KUBE-SERVICES all -- * * 0.0.0.0/0 0.0.0.0/0 /* kubernetes service portals */
2311 344K DOCKER all -- * * 0.0.0.0/0 0.0.0.0/0 ADDRTYPE match dst-type LOCAL
Chain OUTPUT (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
19039 1541K KUBE-SERVICES all -- * * 0.0.0.0/0 0.0.0.0/0 /* kubernetes service portals */
1625 97500 DOCKER all -- * * 0.0.0.0/0 !127.0.0.0/8 ADDRTYPE match dst-type LOCAL
由于两个链的处理过程一样,这里我们主要看对 PREROUTING 链的处理过程。
后面的过程中会经常用到 KUBE-MARK-MASQ 链,它的作用是为需要进行源地址转换(SNAT)的流量设置一个标记(MARK)。
Chain KUBE-MARK-MASQ (154 references)
pkts bytes target prot opt in out source destination
9 540 MARK all -- * * 0.0.0.0/0 0.0.0.0/0 MARK or 0x4000
当我们在其它机器上执行命令
$ curl -D- http://192.168.1.200 -H 'Host: myserviceb.foo.org'
此时一个外部数据包根据 ARP 记录流入到本机,此时会经过 iptables,首先数据包流入到 NAT 表的 PREROUTING 链,根据匹配规则再进入到 KUBE-SERVICES 链。
Chain KUBE-SERVICES (2 references)
pkts bytes target prot opt in out source destination
0 0 KUBE-EXT-CG5I4G2RS3ZVWGLK tcp -- * * 0.0.0.0/0 192.168.1.200 /* ingress-nginx/ingress-nginx-controller:http loadbalancer IP */
0 0 KUBE-EXT-EDNDUDH2C75GIR6O tcp -- * * 0.0.0.0/0 192.168.1.200 /* ingress-nginx/ingress-nginx-controller:https loadbalancer IP */
...
此时根据 iptables 规则从上到下开始执行,当根据目标地址匹配到了 192.168.1.200 这个 LoadBalancer IP 时,将自动进入链 KUBE-EXT-CG5I4G2RS3ZVWGLK。
这里有两条规则分别匹配
HTTP和HTTPS协议,它们的处理过程完全一样,这里我们只分析对 HTTP 协议的处理过程。
链:KUBE-SERVICES -> KUBE-EXT-CG5I4G2RS3ZVWGLK
Chain KUBE-EXT-CG5I4G2RS3ZVWGLK (2 references)
pkts bytes target prot opt in out source destination
0 0 KUBE-SVC-CG5I4G2RS3ZVWGLK all -- * * 10.244.0.0/16 0.0.0.0/0 /* pod traffic for ingress-nginx/ingress-nginx-controller:http external destinations */
0 0 KUBE-MARK-MASQ all -- * * 0.0.0.0/0 0.0.0.0/0 /* masquerade LOCAL traffic for ingress-nginx/ingress-nginx-controller:http external destinations */ ADDRTYPE match src-type LOCAL
0 0 KUBE-SVC-CG5I4G2RS3ZVWGLK all -- * * 0.0.0.0/0 0.0.0.0/0 /* route LOCAL traffic for ingress-nginx/ingress-nginx-controller:http external destinations */ ADDRTYPE match src-type LOCAL
0 0 KUBE-SVL-CG5I4G2RS3ZVWGLK all -- * * 0.0.0.0/0 0.0.0.0/0
这里规则主要针对三种情况进行处理
- 数据包来自 POD (掩码 10.244.0.0/16),进入链
KUBE-SVC-CG5I4G2RS3ZVWGLK - 本节点流量,即访问本机服务,同样进入链
KUBE-SVC-CG5I4G2RS3ZVWGLK,但需要先进行 MARK 标记 - 其它未匹配的流量进入链
KUBE-SVL-CG5I4G2RS3ZVWGLK
ADDRTYPE match src-type LOCAL 这部分的意思是: ADDRTYPE match 表示使用地址类型扩展匹配 src-type LOCAL 表示匹配源地址类型为本地地址 所谓本地地址,指的是源自本节点上的流量,包括本节点上运行的 Pod 等产生的流量。
这条规则的作用是为 ingress-nginx-controller 这个服务的 HTTPS 外部流量进行 SNAT (源地址转换),也就是进行源地址伪装。
通过 ADDRTYPE match src-type LOCAL 这一条件,它只会对源自本节点上的流量进行 SNAT,而不会影响来自其他节点或外部的流量的源地址
这里前两种情况都是进入链 KUBE-SVC-CG5I4G2RS3ZVWGLK, 其它情况进入 KUBE-SVL-CG5I4G2RS3ZVWGLK。
链:KUBE-SERVICES -> KUBE-EXT-CG5I4G2RS3ZVWGLK -> KUBE-SVC-CG5I4G2RS3ZVWGLK
Chain KUBE-SVC-CG5I4G2RS3ZVWGLK (3 references)
pkts bytes target prot opt in out source destination
0 0 KUBE-MARK-MASQ tcp -- * * !10.244.0.0/16 10.103.50.74 /* ingress-nginx/ingress-nginx-controller:http cluster IP */
0 0 KUBE-SEP-R6ARDBXZLKHCK76A all -- * * 0.0.0.0/0 0.0.0.0/0 /* ingress-nginx/ingress-nginx-controller:http -> 10.244.0.41:80 */
第一条规则表示如果来源 IP 地址为非 POD 且目标地址为 service IP,则进行 MARK 标记,进行 SNAT。
第二条规则表示所有流量进入链 KUBE-SEP-R6ARDBXZLKHCK76A.
链:KUBE-SERVICES -> KUBE-EXT-CG5I4G2RS3ZVWGLK -> KUBE-SVC-CG5I4G2RS3ZVWGLK -> KUBE-SEP-R6ARDBXZLKHCK76A
Chain KUBE-SEP-R6ARDBXZLKHCK76A (2 references)
pkts bytes target prot opt in out source destination
0 0 KUBE-MARK-MASQ all -- * * 10.244.0.41 0.0.0.0/0 /* ingress-nginx/ingress-nginx-controller:http */
0 0 DNAT tcp -- * * 0.0.0.0/0 0.0.0.0/0 /* ingress-nginx/ingress-nginx-controller:http */ tcp to:10.244.0.41:80
这里第一条规则表示所有流量进入10.244.0.41:80, 其正是 ingress-nginx-controller 服务的 pod IP.
$ kubectl get pods -n ingress-nginx -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
ingress-nginx-admission-create-wg5br 0/1 Completed 0 12d <none> ubuntu <none> <none>
ingress-nginx-admission-patch-l7wqg 0/1 Completed 0 12d <none> ubuntu <none> <none>
ingress-nginx-controller-6bfd765bdc-876lz 1/1 Running 11 (152m ago) 12d 10.244.0.41 ubuntu <none> <none>
我们再看一下另一个链
链:KUBE-SERVICES -> KUBE-EXT-CG5I4G2RS3ZVWGLK -> KUBE-SVL-CG5I4G2RS3ZVWGLK -> KUBE-SEP-R6ARDBXZLKHCK76A
Chain KUBE-SVL-CG5I4G2RS3ZVWGLK (1 references)
pkts bytes target prot opt in out source destination
0 0 KUBE-SEP-R6ARDBXZLKHCK76A all -- * * 0.0.0.0/0 0.0.0.0/0 /* ingress-nginx/ingress-nginx-controller:http -> 10.244.0.41:80 */
可以看到它与KUBE-SVC-CG5I4G2RS3ZVWGLK链的区别只是少了一行添加 MARK 的规则,最终仍是进入到 KUBE-SEP-R6ARDBXZLKHCK76A 链,最终到达 ingress-nginx-controller 服务的 pod IP。
而这个 ingress-nginx-controller pod 是一个运行 Nginx 服务的反射代理服务器。其 nginx.conf 配置内容如下:
$ kubectl exec -it ingress-nginx-controller-6bfd765bdc-876lz -n ingress-nginx -- cat /etc/nginx/nginx.conf
总结
- 流量从外部流入集群节点,主要是通过 metalLB 进行 arp 响应来实现的。另外此节点并不一定是 master 节点,原因见 layer2 模式的介绍 https://metallb.universe.tf/concepts/layer2/
- 当流量到达节点后,主要通过 iptables 将流量流入到 ingress-nginx-controller 这个 pod,这里 nginx 扮演的是一个反向代理的角色。
参考
- https://metallb.universe.tf/concepts/layer2/
- https://blog.haohtml.com/posts/install-kubernetes-in-raspberry-pi/